Application
Elastic Transcoder
- Media transcoder in the cloud.
API Gateway
- API Gateway Options
- API Gateway Configuration
- API Gateway Deployment
- API Gateway Caching : increase performance
- Same Origin Policy : A web browser permits scripts contained in a first web page to access data in a second web page. This is done to prevent Cross-Site Scripting(XSS) attacks.
- CORS(Cross-Origin Resource Sharing) : allows restricted resources to be requested from another domain
- If you are using Javascript/AZAX that uses multiple domains with API Gateway, you have to enable CORS on API Gateway
Kinesis
- Streaming Data : Purchases from online stores, Stock Prices, Game data, Social network data, Geospatial data(uber), IoT sensor data
3 Types of Kinesis
- Kinesis Streams
- Shards : the total capacity of the stream is the sum of the capacities of its shards.
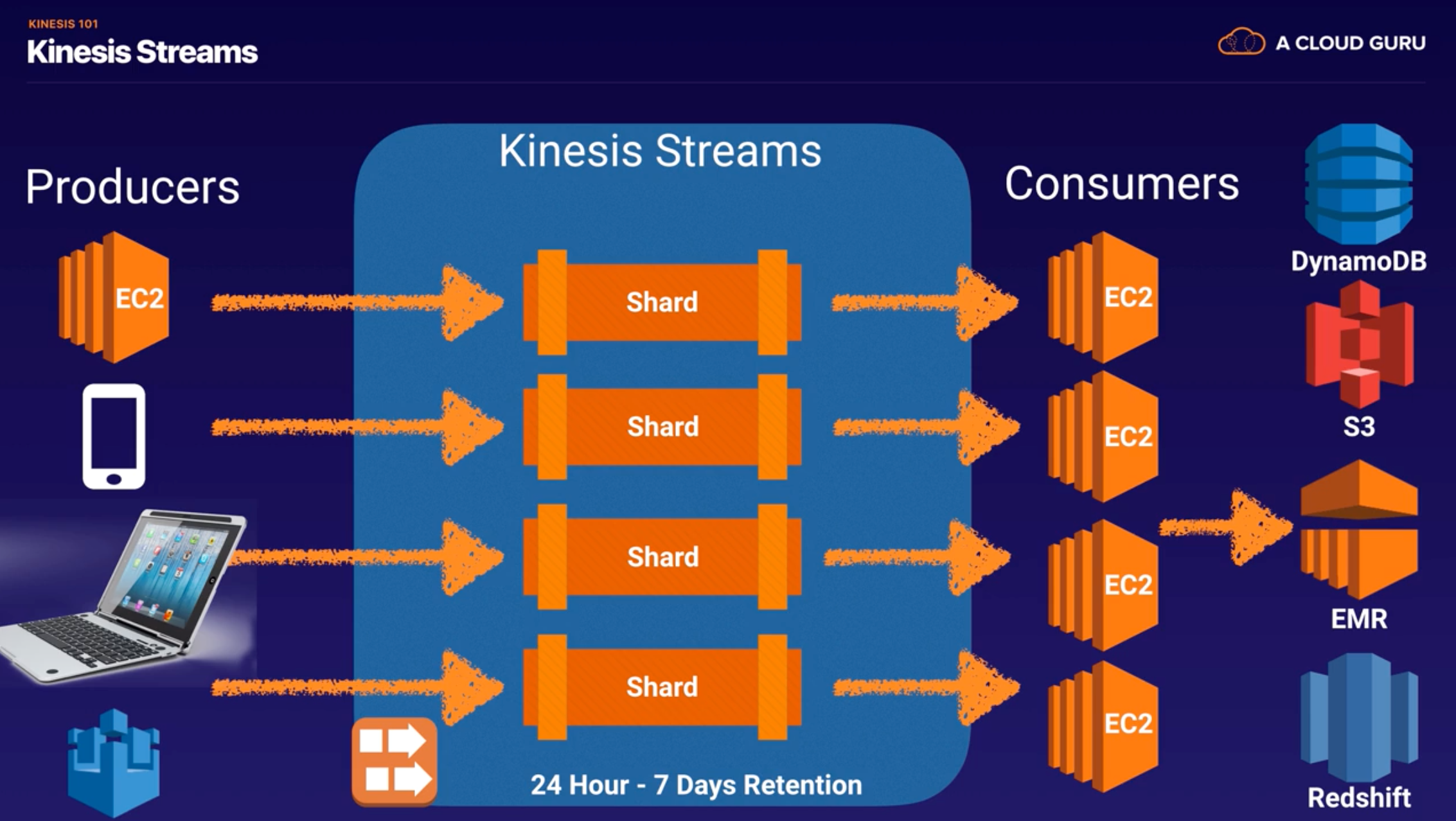
- Shards : the total capacity of the stream is the sum of the capacities of its shards.
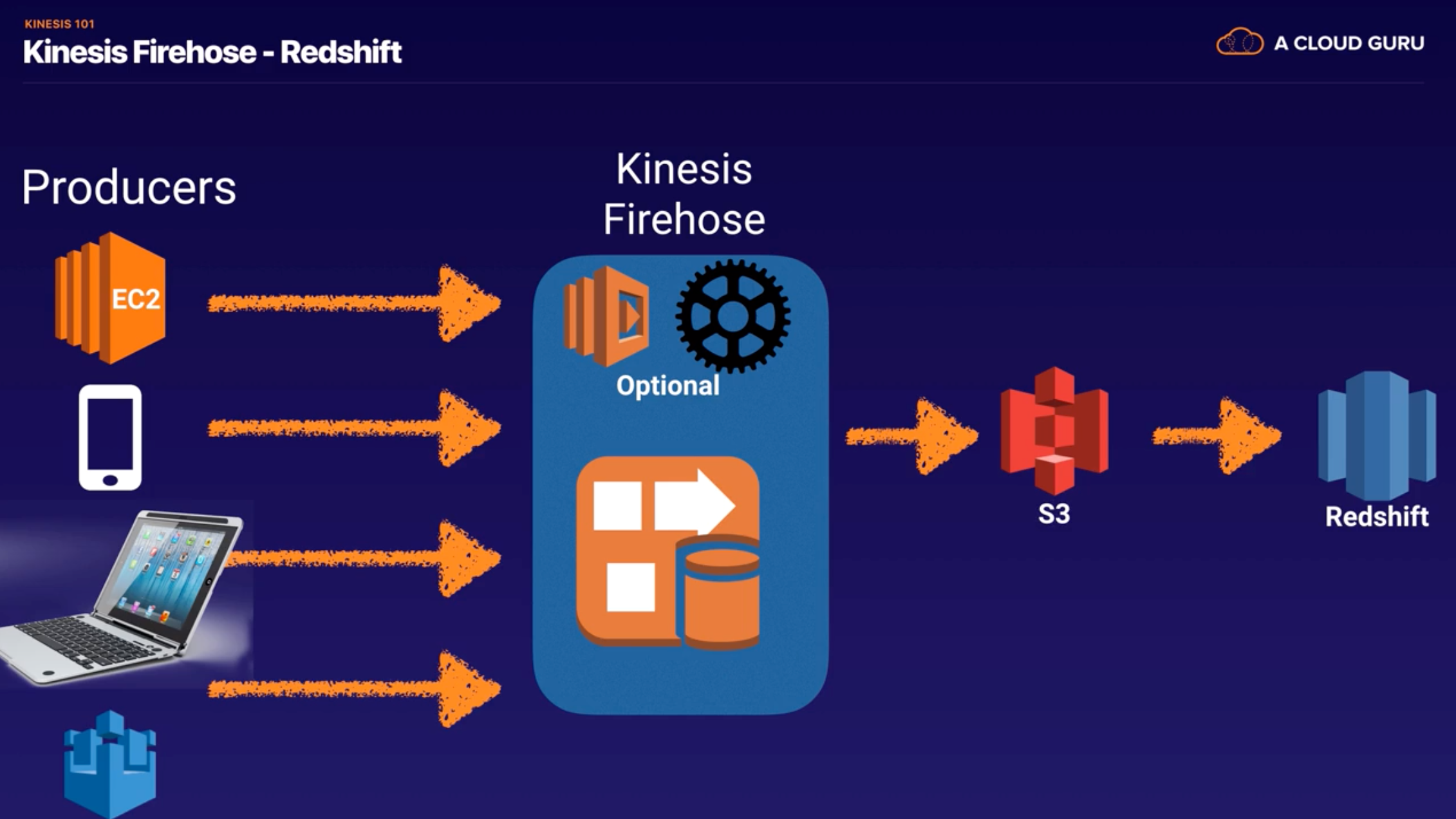
- Kinesis Firehose
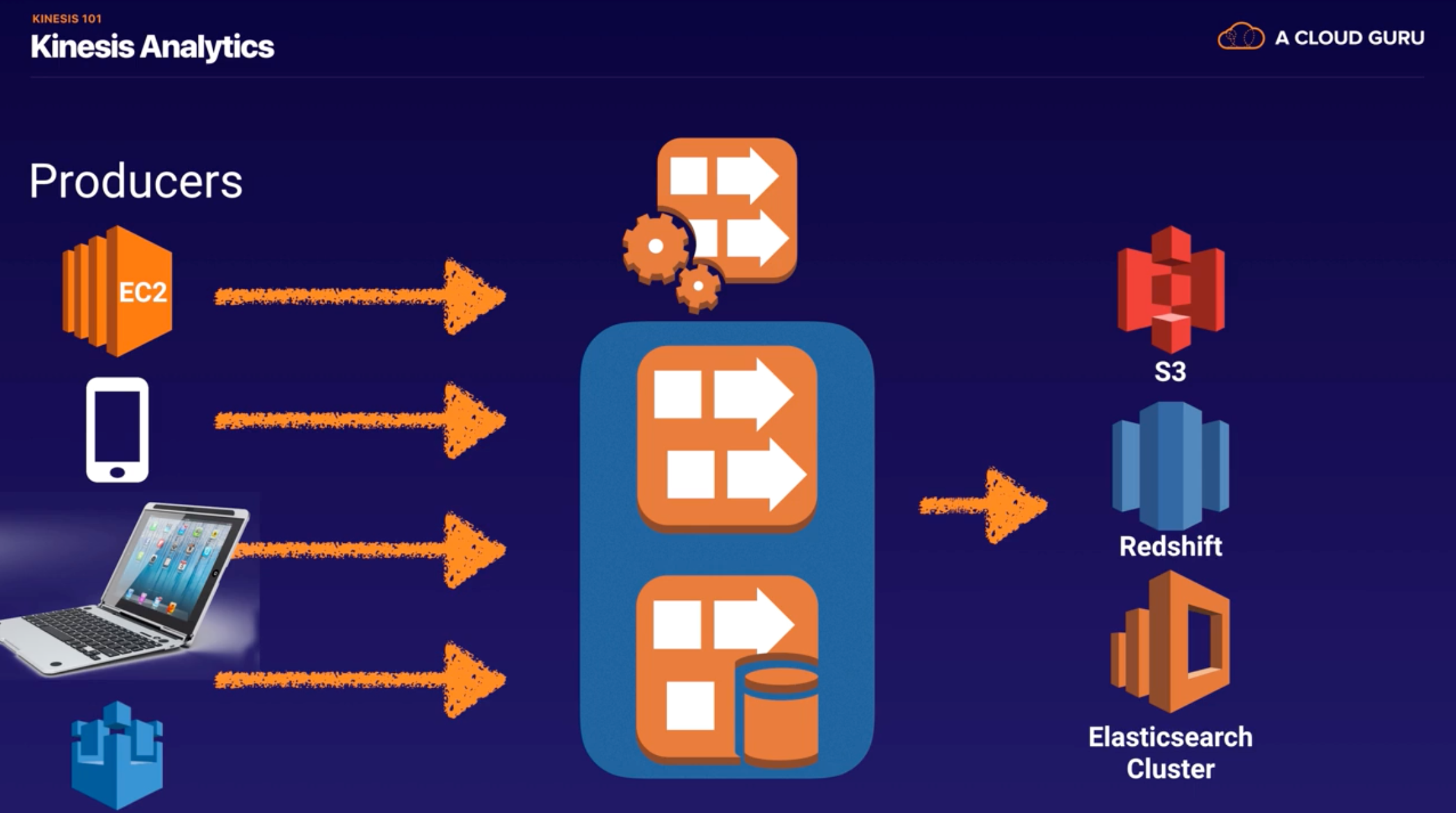
- Kinesis Analytics
IoT Core
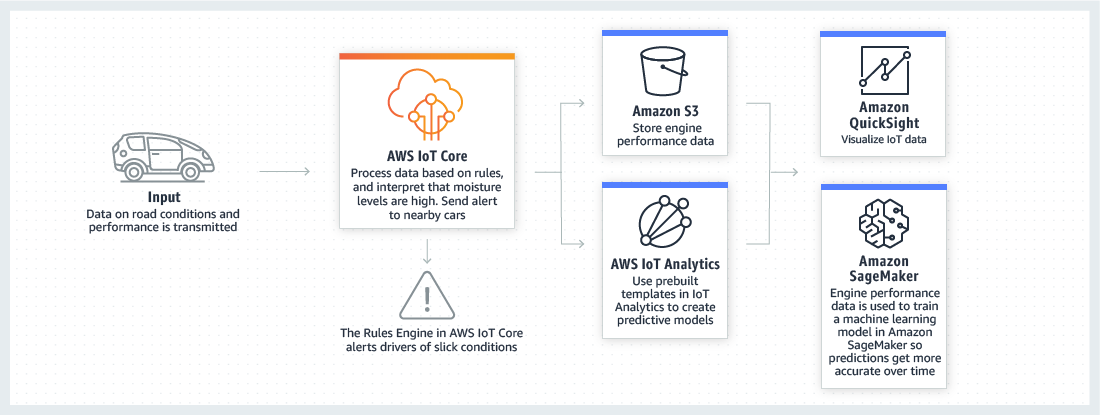
- a managed cloud service that lets connected devices easily and securely interact with cloud applications and other devices.
- provides secure communication and data processing across different kinds of connected devices and locations so you can easily build IoT applications.
Scenario
- A traffic monitoring and reporting application uses Kinesis to accept real-time data. In order to process and store the data, they used Amazon Kinesis Data Firehose to load the streaming data to various AWS resources.
Which of the following services can you load streaming data into?- A) Amazon Elasticsearch Service
- Amazon Kinesis Data Firehose : capture, transform, and load streaming data into Amazon S3, Amazon Redshift, Amazon Elasticsearch Service, and Splunk, enabling near real-time analytics with existing business intelligence tools and dashboards you’re already using today.
- S3 Select : is incorrect because S3 Select is just a feature of Amazon S3 that makes it easy to retrieve specific data from the contents of an object using simple SQL expressions without having to retrieve the entire object.
- Redshift Spectrum : is incorrect because Redshift Spectrum is also just a feature of Amazon Redshift that enables you to run queries against exabytes of unstructured data in Amazon S3 with no loading or ETL required.
- A cryptocurrency trading platform is using an API built in AWS Lambda and API Gateway. Due to the recent news and rumors about the upcoming price surge of Bitcoin, Ethereum and other cryptocurrencies, it is expected that the trading platform would have a significant increase in site visitors and new users in the coming days ahead.
In this scenario, how can you protect the backend systems of the platform from traffic spikes?- A) enabling throttling limits and result caching in API Gateway
- throttling : Amazon API Gateway provides throttling at multiple levels including global and by service call. Throttling limits can be set for standard rates and bursts. For example, API owners can set a rate limit of 1,000 requests per second for a specific method in their REST APIs, and also configure Amazon API Gateway to handle a burst of 2,000 requests per second for a few seconds. Amazon API Gateway tracks the number of requests per second. Any request over the limit will receive a 429 HTTP response. The client SDKs generated by Amazon API Gateway retry calls automatically when met with this response.
- caching : The cache is provisioned for a specific stage of your APIs. This improves performance and reduces the traffic sent to your back end. Cache settings allow you to control the way the cache key is built and the time-to-live (TTL) of the data stored for each method. Amazon API Gateway also exposes management APIs that help you invalidate the cache for each stage.
- CloudFront : is incorrect because CloudFront only speeds up content delivery which provides a better latency experience for your users. It does not help much for the backend.
- You are using a combination of API Gateway and Lambda for the web services of your online web portal that is being accessed by hundreds of thousands of clients each day. Your company will be announcing a new revolutionary product and it is expected that your web portal will receive a massive number of visitors all around the globe. How can you protect your backend systems and applications from traffic spikes?
- A) Use throttling limits in API Gateway
- You have a data analytics application that updates a real-time, foreign exchange dashboard and another separate application that archives data to Amazon Redshift. Both applications are configured to consume data from the same stream concurrently and independently by using Amazon Kinesis Data Streams.
However, you noticed that there are a lot of occurrences where a shard iterator expires unexpectedly. Upon checking, you found out that the DynamoDB table used by Kinesis does not have enough capacity to store the lease data.
Which of the following is the most suitable solution to rectify this issue?- A) Increase the write capacity assigned to the shard table.
- Enabling In-Memory Acceleration with DynamoDB Accelerator (DAX) : is incorrect because the DAX feature is primarily used for read performance improvement of your DynamoDB table from milliseconds response time to microseconds.
- You are working as a Cloud Consultant for a government agency with a mandate of improving traffic planning, maintenance of roadways and preventing accidents. There is a need to manage traffic infrastructure in real time, alert traffic engineers and emergency response teams when problems are detected, and automatically change traffic signals to get emergency personnel to accident scenes faster by using sensors and smart devices.
Which AWS service will allow the developers of the agency to connect the said devices to your cloud-based applications?- A) AWS IoT Core
- You are a Solutions Architect of a multi-national gaming company which develops video games for PS4, Xbox One and Nintendo Switch consoles, plus a number of mobile games for Android and iOS. Due to the wide range of their products and services, you proposed that they use API Gateway.
What are the key features of API Gateway that you can tell your client? (Choose 2)- A1) You can run your APIs without any servers.
- A2) You pay only for the API calls you receive and the amount of data transfered out
- You are working for a Social Media Analytics company as its head data analyst. You want to collect gigabytes of data per second from websites and social media feeds to gain insights from data generated by its offerings and continuously improve the user experience. To meet this design requirement, you have developed an application hosted on an Auto Scaling group of Spot EC2 instances which processes the data and stores the results to DynamoDB and Redshift.
Which AWS service can you use to collect and process large streams of data records in real time?- A) Amazon Kinesis Data Streams
- IT infrastructure log data, application logs, social media, market data feeds, and web clickstream data. Because the response time for the data intake and processing is in real time, the processing is typically lightweight.
- S3 : is incorrect because this is mainly used for object storage of frequently and infrequently accessed files with high durability.
- Redshift : is incorrect because this is mainly used for data warehousing making it simple and cost-effective to analyze your data across your data warehouse and data lake.
- You installed sensors to track the number of visitors that goes to the park. The data is sent everyday to an Amazon Kinesis stream with default settings for processing, in which a consumer is configured to process the data every other day. You noticed that your S3 bucket is not receiving all of the data that is being sent to the Kinesis stream. You checked the sensors if they are properly sending the data to Amazon Kinesis and verified that the data is indeed sent everyday.
What could be the reason for this?- A) By default, the data records are only accessible for 24 hours from the time they are added to a Kinesis stream
- retention period : A Kinesis data stream stores records from 24 hours by default to a maximum of 168 hours.
- You are working for a data analytics company as a Software Engineer, which has a client that is setting up an innovative checkout-free grocery store. You developed a monitoring application that uses smart sensors to collect the items that your customers are getting from the grocery’s refrigerators and shelves then automatically maps it to their accounts. To know more about the buying behavior of your customers, you want to analyze the items that are constantly being bought and store the results in S3 for durable storage.
What service can you use to easily capture, transform, and load streaming data into Amazon S3, Amazon Elasticsearch Service, and Splunk?- A) Amazon Kinesis Data Firehose
- Amazon Kinesis : is incorrect because this is the streaming data platform of AWS and has four distinct services under it: Kinesis Data Firehose, Kinesis Data Streams, Kinesis Video Streams, and Amazon Kinesis Data Analytics.
- Amazon Macie : is incorrect because this is mainly utilized as a security service that uses machine learning to automatically discover, classify, and protect sensitive data in AWS.
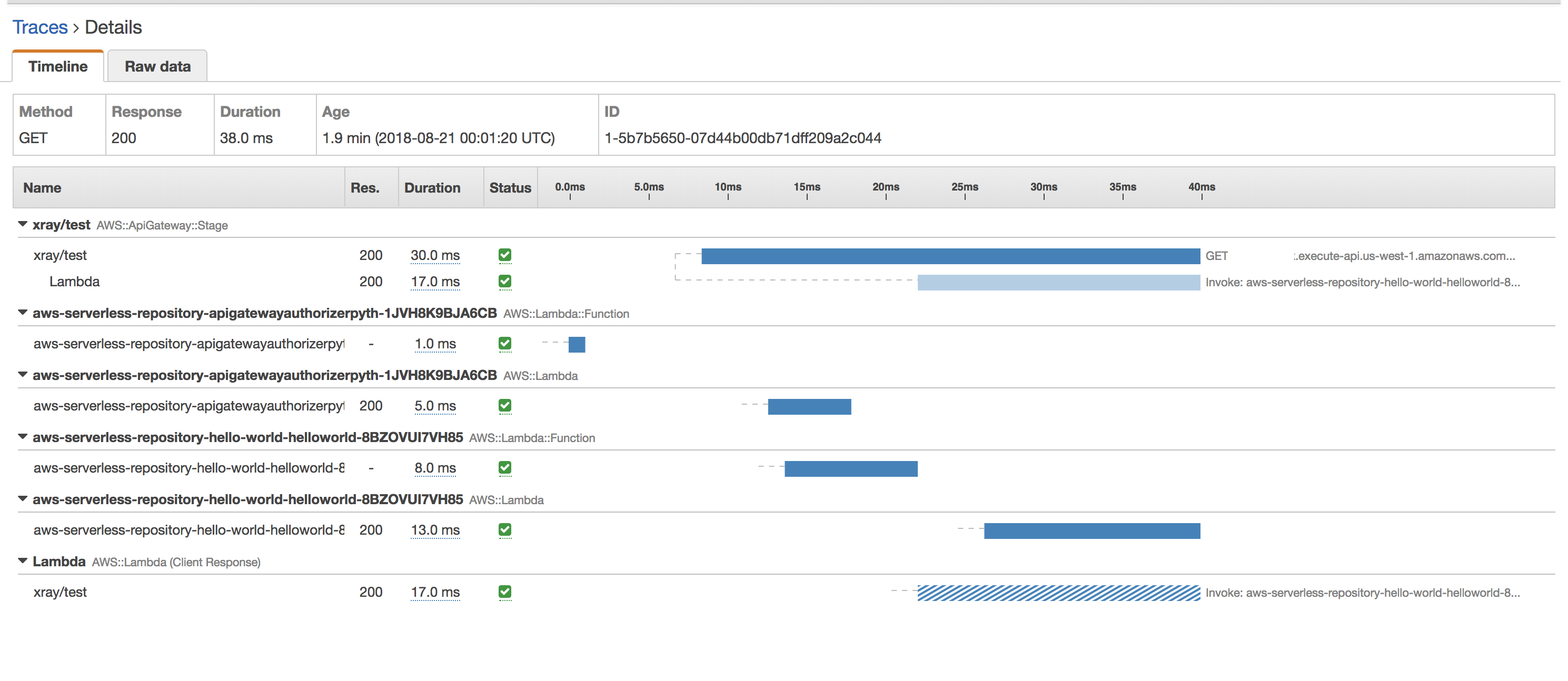
- An application is using a RESTful API hosted in AWS which uses Amazon API Gateway and AWS Lambda. There is a requirement to trace and analyze user requests as they travel through your Amazon API Gateway APIs to the underlying services.
Which of the following is the most suitable service to use to meet this requirement?- A) AWS X-Ray
- X-Ray gives you an end-to-end view of an entire request, so you can analyze latencies in your APIs and their backend services.
-
debug and analyze your microservices applications with request tracing so you can find the root cause of your issues and performance.
- VPC Flow Logs : is incorrect because this is a feature that enables you to capture information about the IP traffic going to and from network interfaces in your entire VPC.
- CloudTrail : is incorrect because this is primarily used for API logging of all of your AWS resources.
- A data analytics application requires a service that can collect, process, and analyze clickstream data from various websites in real-time. Which of the following is the most suitable service to use for the application?
- A) Kinesis
- Redshift Spectrum : is incorrect because this is primarily used to directly query open data formats stored in Amazon S3. it enables you to analyze data across your data warehouse and data lake, together, with a single service. It does not provide the ability to process your data in real-time.
- AWS Glue : is incorrect because this is a fully managed ETL service that makes it easy for customers to prepare and load their data for analytics. It does not provide the ability to process your data in real-time.
- Amazon EMR with Compute Optimized Instances : is incorrect because this is a web service that uses an open-source Hadoop framework to quickly & cost-effectively process vast amounts of data. It does not provide the ability to process your data in real-time. Compute-optimized instances are ideal for compute-bound applications that benefit from high-performance processors but not for analyzing clickstream data from various websites in real-time.
- You are working as a Solutions Architect for a startup in which you are tasked to develop a custom messaging service that will also be used to train their AI for an automatic response feature which they plan to implement in the future. Based on their research and tests, the service can receive up to thousands of messages a day, and all of these data are to be sent to Amazon EMR for further processing. It is crucial that none of the messages will be lost, no duplicates will be produced and that they are processed in EMR in the same order as their arrival.
Which of the following options should you implement to meet the startup’s requirements?- A) Create an Amazon Kinesis Data Stream to collect the messages.
- A Kinesis data stream is a set of shards that has a sequence of data records, and each data record has a sequence number that is assigned by Kinesis Data Streams.
Kinesis can also easily handle the high volume of messages being sent to the service. - SQS : is incorrect. A default queue in SQS is just a standard queue and not a FIFO (First-In-First-Out) queue. In addition, SQS does not guarantee that no duplicates will be sent.
- SNS : is incorrect. SNS mig. ht not be capable of handling such a large volume of messages. It does not also guarantee that the data will be transmitted in the same order they were received.
- AWS Data Pipeline : is incorrect because this is primarily used as a cloud-based data workflow service that helps you process and move data between different AWS services and on-premises data sources. It is not suitable for collecting data from distributed sources such as users, IoT devices, or clickstreams.
- You have just launched a new API Gateway service which uses AWS Lambda as a serverless computing service. In what type of protocol will your API endpoint be exposed?
- A) HTTPS
- Amazon API Gateway를 통해 생성된 모든 API는 HTTPS 엔드포인트만 제공합니다. Amazon API Gateway는 암호화되지 않은(HTTP) 엔드포인트를 지원하지 않습니다. 기본적으로 Amazon API Gateway는 Amazon API Gateway 인증서를 자동으로 사용하는 API에 내부 도메인을 할당합니다. API가 커스텀 도메인 이름에서 실행되도록 구성할 때, 도메인에 대한 자체 인증서를 제공할 수 있습니다.
- You are working for a multinational telecommunications company. Your IT Manager is willing to consolidate their log streams including the access, application, and security logs in one single system. Once consolidated, the company wants to analyze these logs in real-time based on heuristics. There will be some time in the future where the company will need to validate heuristics, which requires going back to data samples extracted from the last 12 hours.
What is the best approach to meet this requirement?- A) First, send all of the log events to Amazon Kinesis then afterwards, develop a client process to apply heuristics on the logs.
- Amazon Kinesis를 사용하면 실시간 스트리밍 데이터를 쉽게 수집, 처리 및 분석 할 수 있으므로 시기 적절한 통찰력을 확보하고 새로운 정보에 신속하게 대응할 수 있습니다. Amazon Kinesis는 애플리케이션의 요구 사항에 가장 적합한 도구를 선택할 수 있는 유연성과 함께 모든 규모의 스트리밍 데이터를 비용 효율적으로 처리 할 수있는 주요 기능을 제공합니다.
- A financial analytics application that collects, processes and analyzes stock data in real-time is using Kinesis Data Streams. The producers continually push data to Kinesis Data Streams while the consumers process the data in real time. In Amazon Kinesis, where can the consumers store their results? (Select TWO.)
- A) Amazon S3, Amazon Redshift
- Amazon Kinesis에서 생산자는 지속적으로 데이터를 Kinesis Data Streams에 푸시하고 소비자는 실시간으로 데이터를 처리합니다. 소비자 (예 : Amazon EC2에서 실행되는 사용자 지정 애플리케이션 또는 Amazon Kinesis Data Firehose 전송 스트림)는 Amazon DynamoDB, Amazon Redshift 또는 Amazon S3와 같은 AWS 서비스를 사용하여 결과를 저장할 수 있습니다.
