[Workflow] AWS 데이터 배치 수집 python / spark 비교
목표
- 전 단지의 전 테이블 데이터 수집
- 새벽 3시에 수행(새벽 2시에 일일데이터사용량 테이블 업데이트 됨)
- 매일 수행
- 최초에 전 데이터 수집 후 1일분의 증분 데이터만 수집
- 테이블에 시간 정보가 존재하면 시간 정보 필드를 이용하여 쿼리, 시간 정보가 없으면 매일 overwrite함
Workflow
완성된 워크플로우를 먼저 보면 다음과 같다.
</br>
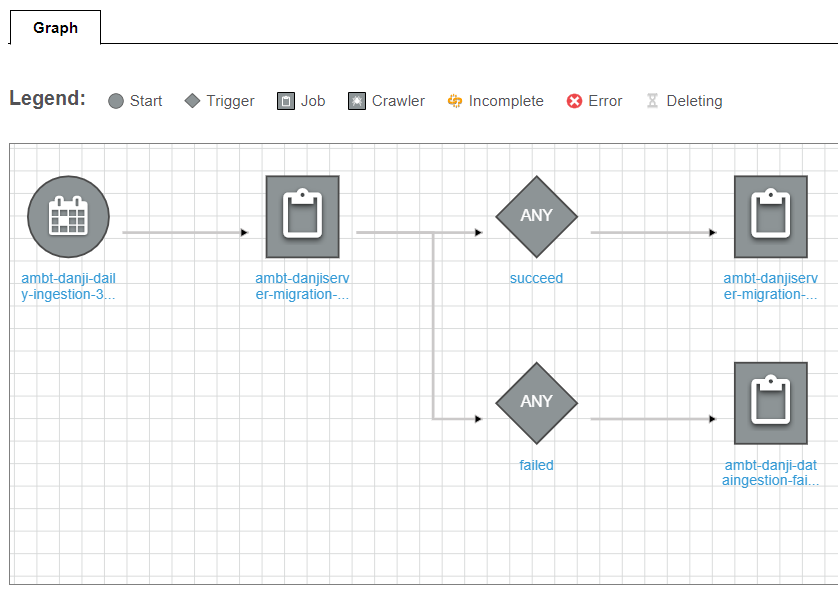
- 새벽 3시 Trigger 발생
- 일일 수집 JOB 실행(약 10분 소요)
- 성공시
- 검증 JOB 실행(약 40분 소요)
- 실패시
- 롤백 JOB 실행(last modified 시간을 기준으로 parquet 파일 삭제)
- 성공시
방안
spark과 python을 비교하여 더 효율적인 방법으로 수집하고자 함
Python
for-loop는 오랜시간 소요되므로 병렬 수행을 위한 concurrent.futures 모듈을 사용
이슈
- concurrent.futures 모듈
- concurrent futures 모듈이 윈도우에서는 정상적으로 동작하지 않음
- aws lambda에서도 정상적으로 동작하지 않음(os error 발생)
- wsl 우분투에서는 동작함
결론
- 파이썬으로 일일 데이터 수집 구현은 아래와 같은 세가지의 방법이 있을 것으로 예상됨
- 병렬적으로 수행되길 기대하는 지점을 람다로 작성하여 람다에서 람다를 호출하는 방법
- aws lambda ec2를 활용해서 병렬성을 구현(https://aws.amazon.com/ko/blogs/compute/parallel-processing-in-python-with-aws-lambda/)
- 세이지메이커에 작성한 노트북을 업로드하고 lifecycle configuration으로 구동 후 정지되는 스크립트 작성하는 방법
- 로컬에서 수행해본 결과 대략 10분 정도 소요됨
SPARK
spark를 사용하기 위한 AWS 서비스는 glue와 emr이 있음 차이점은 glue는 서버리스이고 crawler, trigger등의 etl 관련한 자동화된 툴을 지원함. emr은 서버형으로 개발자가 일일히 지정해야함
aws의 자동화된 서비스를 이용하기 위해서 glue를 사용하기로 함
glue 개발시 aws에서 스크립트 작성 후 job을 수행하여 작업 내용을 확인하는 것은 비효율적임
대안으로 아래와 같이 테스트 환경을 만드는 방법이 있음
- 도커 이미지 활용
- dev endpoint를 만들어서 대화형 노트북(제플린, 주피터)과 연결
먼저 도커 이미지를 생성하여 코드를 검증(정상적으로 작성하였는지, 기대하는 동작을 하는지)한 후 dev endpoint에서 실행
dev endpoint는 glue를 실제 사용하는 것과 같으므로 비용이 발생함, 또한 glue job은 수행 후 종료되면 비용이 발생하지 않는데
dev endpoint는 만들어진 순간부터 사용하든 안하든 비용이 발생함(업무/작업 종료 후 삭제해야함)
Dev Endpoint 생성시 유의사항
- 도커 이미지 다운로드
- 도커 이미지 다운로드 시 docker hub에서 다운로드 받는데 개발 진행 당시에는 docker hub에서 amazon 이미지들이 모두 사라져있었음(현재는 보임)
- 대안으로 aws의 ecr 갤러리(https://gallery.ecr.aws/knowre/aws-glue-libs)에서 다운로드 받아서 진행함
- 윈도우에서 실행시 %UserProfile% 환경변수를 인식하기 위해서 명령프롬프트에서 동작시켜야한다(power shell 불가)
- 윈도우에서 실행시 4040포트는 윈도우에서 관리되고 있는 포트이므로 4040포트는 피해서 동작해야됨
- 개발환경 구성
- 공통
- openssl의 ssh-keygen으로 pulbic key와 private key를 만든다
- public key를 dev endpoint를 만들때 업로드한다
- private key로 ssh 터널을 만든다
- 윈도우에서 사용할때는 윈도우 커맨드에서 도커나 wsl 우분투에서 사용시에는 wsl 우분투창에서 ssh 실행
- 윈도우
- 윈도우 커맨드 창에서 ssh 터널 생성
- 윈도우에서 재플린 실행
- bin/common.cmd 파일 수정
- 77 라인 } –> )수정
- bin/common.cmd 파일 수정
- 도커
- wsl ubuntu에서 ssh 터널 생성
- 제플린 도커 실행
- 인터프리터 connect to existing process에서 host ip를 vm 주소로 변경(localhost -> 172.xx.xx.xx)
- wsl
- wsl ubuntu에서 ssh 터널 생성
- open jdk 8 설치
- 환경변수 java_home 설정
- conf/zeppeline-site.xml에서 server.addr을 0.0.0.0으로 변경
- wsl ubuntu의 vm ip확인 후 브라우저에서 vm의 ip로 접속(172.xx.xx.xx:8080)
- 공통
이슈
- jdbc 테이블 병렬 읽기
- glue의 dynamicframe은 jdbc로 데이터 로드시 병렬읽기를 지원함,
- connection_options에 hashfield, hashexpression, hashpartitions을 작성하면 테이블 로드를 병렬로 진행하여 속도가 개선될 것으로 기대함
- 결론적으로 큰 차이 없었음
- glue job 생성시 parameter 전달
- glue에서는 parameter를 제공하여 glue job을 생성할때 parameter를 전달할 수 있음
- 데이터 수집에 대한 내용은 모든 현장이 동일하니 1개의 스크립트를 작성하고 job을 실행하는 코드를 lambda로 작성하여 job을 수행함
- 다수 단지의 다수 테이블을 동시에 수집하려다보니 worker가 많이 필요한대 AWS에서 한 계정단 최대 워커 개수는 300개로 제한됨
- 300개보다 더 많이 필요함
- concurrent.futures 모듈 사용
- python의 병렬성 모듈인 concurrent.futures을 사용
- 106개의 현장을 접속하는 프로세스 풀을 만들고 그 프로세스 풀에서 70여개의 테이블을 접속하는 프로세스 풀을 만들어서 병렬로 데이터 수집을 시도하였으나 스파크에서 concurrent.futures 모듈을 정상적으로 구동되지 않음.
- spark 또한 병렬성을 지원하므로 충돌이 발생하는 것으로 예상됨
- 기타 함수 활용
- foreach나 withcolumn에서 udf로 병렬로 데이터 수집을 시도해보았으나 기대했던 동작을 하지 않음
- dynamicframe에서 spark dataframe으로 변경
- glue의 dynamicframe을 사용하여 시도하였으나 query하여 데이터를 일부 로드하는 방식은 jdbc에서는 지원하지 않음
- 항상 전체 데이터를 load후 일일 filter를 해야하는데 이 과정에서 병목현상이 심함
- spark dataframe으로 일일 query하는 방식으로 변경함
- 0000-00-00 00:00:00 이슈
- visitor_history 테이블의 일부 컬럼이 datetime 타입임
- 해당 컬럼에 0000-00-00 00:00:00 데이터가 존재
- java.sql.timestamp 모듈은 해당 데이터를 인식하지 못함
- 해당 데이터를 null로 replace하기 위해 dataframe의 datatype을 string으로 형변환 시도함
- 하지만 형변환 하는 과정에서 오류가 발생함
- read할 때 url 마지막에 ?zeroDateTimeBehavior=convertToNull 파라메터를 추가하여 해결
glue job 스크립트
import sys
import boto3
import json
import time
import os
import logging
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.dynamicframe import DynamicFrame
from awsglue.job import Job
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType
from pyspark.sql.types import IntegerType
from multiprocessing.pool import ThreadPool
from pyspark.sql.functions import lit
from datetime import timedelta, datetime
logger = logging.getLogger()
logger.setLevel(logging.INFO)
os.environ['TZ']='Asia/Seoul'
time.tzset()
start = time.time()
# user define function 생성
chop_f = udf(lambda x: x[8:], StringType())
year_f = udf(lambda x: x.year, IntegerType())
month_f = udf(lambda x: x.month, IntegerType())
cloudwatch = boto3.client('cloudwatch',region_name='ap-northeast-2')
### cloudwatch put metric ###
def put_cloudwatch_metric(metric_data):
if metric_data:
try :
cloudwatch.put_metric_data(
Namespace='Glue/danji-ingestion-count',
MetricData= metric_data
)
except Exception as e:
logger.error(e)
# 각 테이블 접속
def table_migration(table, url_code):
url = "jdbc:mysql://{}:3306/DB_NAME?zeroDateTimeBehavior=convertToNull".format(url_code.url)
if table in nodate_table_list :
query = "select * from {}".format(table)
else :
if table == 'park' :
query = "select * from {} where park_date >= '{}' and park_date < '{}'".format(table, yesterday.strftime('%Y-%m-%d'), today.strftime('%Y-%m-%d'))
elif table == 'sdb_reserv' :
query = "select * from {} where regi_date >= '{}' and regi_date < '{}'".format(table, yesterday.strftime('%Y-%m-%d'), today.strftime('%Y-%m-%d'))
elif table == 'dayenergy' :
query = "select * from {} where energy_year={} and energy_month={} and energy_day={}".format(table, yesterday.year, yesterday.month, yesterday.day)
elif table == 'monthenergy' :
query = "select * from {} where energy_year={} and energy_month={}".format(table, yesterday.year, yesterday.month)
else :
query = "select * from {} where created_at >= '{}' and created_at < '{}'".format(table, yesterday.strftime('%Y-%m-%d'), today.strftime('%Y-%m-%d'))
df_table = spark.read.format("jdbc")\
.option("driver", "com.mysql.jdbc.Driver")\
.option("url", url)\
.option("user", "valley")\
.option("password", "valley123")\
.option("query", query)\
.load()
#if not df_table.rdd.isEmpty() :
if table in nodate_table_list :
output_dir= 's3://RAW_DATA_S3_PATH/table_name={}/site_code={}'.format(table, url_code.code)
df_table.write.mode("overwrite").format("parquet").save(output_dir)
else :
output_dir= 's3://RAW_DATA_S3_PATH/table_name={}/site_code={}/year={}/month={}'.format(table, url_code.code, yesterday.year, yesterday.month)
if table == 'monthenergy':
df_table.write.mode("overwrite").format("parquet").save(output_dir)
else :
df_table.write.mode("append").format("parquet").save(output_dir)
'''
put_cloudwatch_metric([{
'Dimensions': [
{
'Name': 'SiteCode',
'Value': url_code.code
},
{
'Name': 'TableName',
'Value': table
}
],
'MetricName': 'IngestionCount',
'Unit': 'Count',
'Value': df_table.count()
},
{
'Dimensions': [
{
'Name': 'TableName',
'Value': table
}
],
'MetricName': 'IngestionCount',
'Unit': 'Count',
'Value': df_table.count()
}])
'''
# 각 사이트 접속
def site_connection(url_code):
try :
#각 사이트 접속 후 테이블 목록으로 프레임 생성
df = spark.read.format("jdbc")\
.option("driver", "com.mysql.jdbc.Driver")\
.option("url", "jdbc:mysql://{}:3306/information_schema?connectTimeout=5000".format(url_code.url))\
.option("user", "{수집DB_ID}")\
.option("password", "{수집DB_PASSWORD}")\
.option("query", "SELECT * FROM TABLES")\
.load()
#DB_NAME 스키마의 테이블 목록만 필터링
df_filter = df.filter(df.TABLE_SCHEMA=='DB_NAME')
table_list = df_filter.select('TABLE_NAME').collect()
table_array = [row.TABLE_NAME for row in table_list]
logger.info(url_code.url)
pool_table = ThreadPool(4)
pool_table.map(lambda x:table_migration(x,url_code), table_array)
except Exception as e:
errorlist.append("{} {}".format(url_code.url, str(e).split('\n')[0:2]))
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
spark.conf.set("mapreduce.fileoutputcommitter.cleanup-failures.ignored", "true")
spark.conf.set("spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version", "2")
connection_mysql5_options = {
"url": "jdbc:mysql://{RDS_HOST_URL이 들어갑니다}:3306/ambt",
"dbtable": "{dbtable}",
"user": "{RDS_DB_ID}",
"password": "{RDS_DB_PASSWORD}"}
# Read DynamicFrame from MySQL 5 and write to MySQL 8
df_mysql5 = glueContext.create_dynamic_frame.from_options(connection_type="mysql",
connection_options=connection_mysql5_options)
# 아이파크와 대외 현장만 필터
df_mysql5_filter = Filter.apply(frame=df_mysql5, f=lambda x:x['brand']=='아이파크' or x['brand']=='대외')
# 특정 현장필터
#df_mysql5_filter = Filter.apply(frame=df_mysql5_filter, f=lambda x:x['code']=='31440003')
# code와 url 컬럼만 추출
df_selectFields = SelectFields.apply(frame = df_mysql5_filter, paths=['code', 'url'])
df_selectFields_dataframe = df_selectFields.toDF()
# https:// 제외한 url만 추출
df_url_code_dataframe = df_selectFields_dataframe.withColumn('url', chop_f(df_selectFields_dataframe['url']))
# timestamp나 datetime 컬럼이 없는 테이블들의 목록
nodate_table_list = ['alarm_cause', 'alarm_mode', 'elevator_floor', 'entrance_code', 'migrations', 'sdb_reserv_device']
#오늘
today = datetime.now()
#today = datetime.strptime('2021-11-16','%Y-%m-%d')
#어제
yesterday = today-timedelta(days=1)
errorlist = [datetime.fromtimestamp(start).strftime('%Y-%m-%d %H:%M:%S')]
#url dataframe을 list로 변경
url_code_list = df_url_code_dataframe.collect()
url_code_array = [row for row in url_code_list]
#url_code_array = url_code_array[0:1]
#스레드 풀 생성
pool_site = ThreadPool(10)
pool_site.map(lambda x:site_connection(x), url_code_array)
if len(errorlist)>1 :
sns = boto3.client("sns")
sns.publish(TopicArn='{SNS_TOPIC_ARN}', Message='\n'.join(str(e) for e in errorlist), Subject="daily ingestion error list")
end=time.time()
logger.info(end-start)
put_cloudwatch_metric([
{
'Dimensions': [
{
'Name': 'JobName',
'Value': args['JOB_NAME']
}
#,
#{
# 'Name': 'JobRunId',
# 'Value': args['JOB_RUN_ID']
#}
#
],
'MetricName': 'ElapsedTime',
'Unit': 'Seconds',
'Value': end-start
},
{
'Dimensions': [
{
'Name': 'JobName',
'Value': args['JOB_NAME']
}
#,
#{
# 'Name': 'JobRunId',
# 'Value': args['JOB_RUN_ID']
#}
#
],
'MetricName': 'Success Site',
'Unit': 'Count',
'Value': len(url_code_array) - (len(errorlist)-1)
},
{
'Dimensions': [
{
'Name': 'JobName',
'Value': args['JOB_NAME']
}
#,
#{
# 'Name': 'JobRunId',
# 'Value': args['JOB_RUN_ID']
#}
#
],
'MetricName': 'Error Site',
'Unit': 'Count',
'Value': len(errorlist)-1
}])
결론
- spark dataframe으로 jdbc query를 사용하여 일일 데이터만 read함
- python의 threadpool을 사용하여 코드상에서 병렬적으로 데이터 수집을 진행함
- 사이트 접속을 위한 pool을 만들고 사이트 접속 후 테이블 접속 pool을 만들어 데이터를 수집
- 각 파라메터별 속도 벤치마크 결과
| DPU | Site Pool | Table Pool | 소요시간(초) | 소요시간(분) | 월예상요금($) |
|---|---|---|---|---|---|
| 2 | 10 | 4 | 524 | 9 | 3.96 |
| 5 | 7 | 3 | 682 | 12 | 13.2 |
| 5 | 10 | 4 | 533 | 9 | 9.9 |
| 10 | 6 | 4 | 647 | 11 | 24.2 |
| 10 | 7 | 3 | 552 | 10 | 22 |
| 10 | 10 | 4 | 484 | 9 | 19.8 |
| 10 | 20 | 2 | 998 | 17 | 37.4 |
| 10 | 20 | 5 | 619 | 11 | 24.2 |
최종 결론
- spark dataframe을 사용한 스크립트를 활용하여 glue 서비스에서 일일 데이터 수집
- dpu는 2개를 사용하므로 할당 수집 비용은 약 $4 예상
- 시간 소요는 약 10분으로 예상
