[논문리뷰]Attentional factorization machines: Learning the weight of feature interactions via attention networks(2017)
Attentional FM(2017)
Xiao, Jun, et al. “Attentional factorization machines: Learning the weight of feature interactions via attention networks.” arXiv preprint arXiv:1708.04617 (2017). 420회 인용
Why This Paper?
- 기존 FM, DeepFM은 feature interaction의 중요도를 알 수 없다.
- Attentional FM은 이 아이디어에 근거하여, 각기 다른 feature interaction 간의 중요도에 집중하는 attentional score를 추가한다.

FM의 한계
- FM은 모든 factorized된 feature interaction들이 같은 가중치를 갖는다. 모든 feature가 유용하지는 않으므로, feature interaction의 중요도를 달리 선정하지 못한다는 문제가 있다.

w0는 전역 바이어스이고, wi는 i번째 피쳐의 가중치이며, wij는 교차 특징 xixj의 가중치를 나타내며, wij = vTivj로 분해됨
문제점)
- 첫째, 잠재적 벡터 vi는 i번째 기능이 포함하는 모든 기능 상호작용을 추정하는 데 공유됨
- 둘째, 추정된 모든 특징 상호작용(wij)은 같은 균일한 가중치를 갖음. 실제로, 모든 특징이 예측과 관련되는 것은 아님
Attentional FM : Model
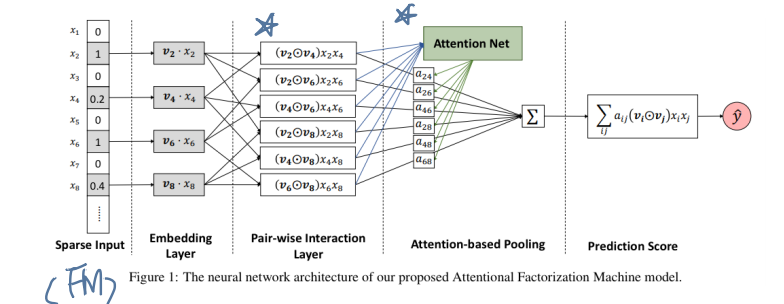
- Input , Embedding Layer는 FM과 같다. (sparse matrix를 dense layer로 만듬)
- 그 다음 이 연구에서는 pair-wise interaction layer, attention based layer를 붙여 공헌하고 있음
Pair-wise Interaction Layer
- inner product을 사용하여 각 피쳐 간 상호 작용을 모델링하는 FM에 영감을 받아 신경망 모델링에서 pair-wise interaction layer 제안
- m벡터를 m(m-1)/2 interacted 벡터로 확장한다.
- 각 interacted 벡터는, interaction을 인코딩하는 개별 두 개의 벡터의 원소곱이다. (element-wise product)
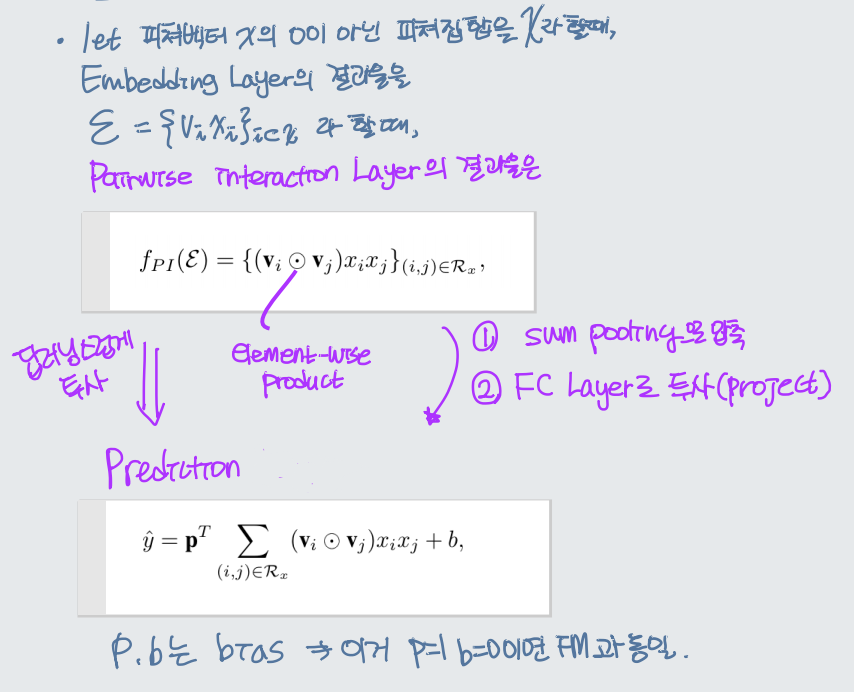
- 이 Layer를 정의하면서, FM을 신경망 구조로 표현할 수 있게 된다. f_PI를 sum pooling으로 압축한다음, Fully Connected Layer를 사용하여 prediction score에 투사(project)한다.
Attention Pooling Layer
- Attention ? : 여러 개의 부분이 압축 과정에 있어서 각각 다르게 기여하여 하나로 표현되도록 만드는 것
Attention Score
-
a는 feature interaction w의 attention score

-
interacted 벡터들의 가중 합을 수행하여 피쳐 상호작용에 대해 Attention 메커니즘을 적용
Attention Network
- Prediction 학습을 진행하면서 attention score a를 추정한다면, 학습데이터에서 한번도 동시에 등장한적 없는 feature들의 경우 feature interaction이 없어 attention score가 추정될 수 없다!
-
따라서 MLP를 통해 attention score를 파라미터화하는 attention network를 추가

- 이 네트워크의 input은 2개 feature의 interacted 벡터인데, 이들의 feature interaction 정보는 임베딩 공간에 인코딩된다.
AFM 최종 수식
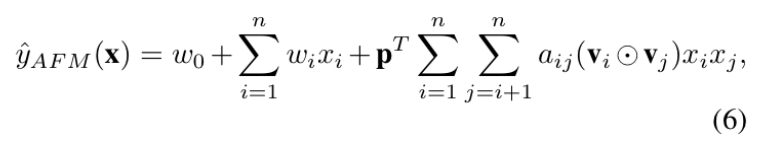
Learning : 과적합 해결
- AFM은 FM보다 표현력이 뛰어나기 때문에 과적합 문제에 민감할 수 있음. 따라서 dropout과 L2 Regularization 테크닉 사용
Conclusions
- feature importance를 반영한 FM 달성
- AttentionalFM 논문 구현
