[논문리뷰]Autofis: Automatic feature interaction selection in factorization models for click-through rate prediction(2020)
AutoFIS : Automatic feature interaction selection in factorization models
Liu, Bin, et al. “Autofis: Automatic feature interaction selection in factorization models for click-through rate prediction.” Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020.
Reference count 50
Why This Paper?
- Feature Interaction Selection + FM에 attention unit을 적용
- 어떤 feature interaction이 필수적인지 자동으로 학습하기 위해 각 feature interaction에 대한 게이트를 도입하여 출력을 다음 계층으로 전달해야 하는지 여부를 제어
- 게이트 개폐로 효율적인 FS를 제시함.
- 이 게이트 개념을 FIR + FM에 녹일 수 있지 않을까? 하는 생각에서 시작
Abstract
- 추천 시스템에서 효과적인 기능 상호 작용을 학습하는 것은 CTR 추정 작업에 매우 중요합니다.
- 본 논문에서는 2단계 알고리즘인 AutoFIS(Automatic Feature Interaction Selection)를 제안하며, Factorization 모델에서 중요한 기능 상호작용을 자동으로 식별할 수 있으며, 계산 비용은 수렴을 위한 모델 훈련의 계산 비용과 동일합니다.
-
- 검색 단계 (Search Stage)
-
아키텍처 매개변수를 도입하고 정규화된 최적화 프로그램을 사용하여 이러한 매개변수를 학습합니다. 이 단계에서 아키텍처 매개변수의 역할은 잘못된 기능 상호 작용을 제거하는 것입니다.
-
- 재훈련 단계 (Retrain Stage)
-
검색 단계의 결과에 따라 중복된 기능 상호 작용을 제거하고 아키텍처 매개변수를 유지하여 모델을 재학습합니다. 이때 이러한 아키텍처 매개변수는 attention unit과 동일합니다.
-
1. Introduction
- 추천 시스템의 핵심은 중요한 저차 및 고차 기능 상호 작용을 추출하는 것
- 그러나 모든 상호 작용이 성능에 도움이 되는 것은 아님. 유용한 interaction을 자동으로 찾기 위해 일부 트리 기반 방법이 제안
- GBDT(Gradient Boosting Decision Tree)
- AutoCross는 트리 구조의 공간에서 효과적인 상호 작용을 검색합니다.
- 그러나 트리 모델은 다중 필드 범주 데이터가 있는 추천 시스템에서 가능한 모든 기능 상호 작용의 작은 부분만 탐색할 수 있으므로 탐색 능력이 제한됩니다.
- 한편 DNN(Deep Neural Network) 모델[6, 30]이 제안된다. 그들의 표현 능력은 더 강력하고 보편적 근사 속성에 따라 대부분의 기능 상호 작용을 탐색할 수 있습니다[11].
- 그러나 DNN이 그래디언트 기반 최적화를 사용하여 예상되는 함수로 자연스럽게 수렴된다는 보장은 없습니다. 최근 연구는 대상이 상관(relative)되지 않은 함수의 대규모 모음일 때 DNN의 둔감한 그래디언트 문제. 단순 DNN 모델은 적절한 기능 상호 작용을 찾지 못할 수 있습니다.
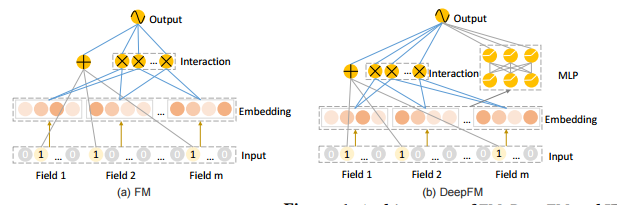
- 따라서, Deep Interest Network(DIN), Deep Factorization Machine(DeepFM), Product-based NeuralNetwork(PNN), Wide & Deep과 같은 다양한 복잡한 아키텍처가 제안되었습니다. FM, DeepFM, PNN, AFM, NFM과 같은 Factorization 모델은 명시적 기능 상호작용을 탐색하기 위해 기능 추출기(feature extractor)를 채택하도록 제안
- 그러나 이러한 모든 모델은 단순히 모든 기능 상호 작용을 열거하거나 중요한 기능 상호 작용을 식별하기 위해 인간의 노력이 필요합니다. 전자는 항상 모델에 큰 메모리와 계산 비용을 가져오고 고차 상호 작용으로 확장하기 어렵습니다. 게다가, 불필요한 상호 작용은 불필요한 소음을 가져오고 훈련 과정을 복잡하게 만들 수 있습니다. Wide& Deep에서 수동으로 중요한 상호 작용을 식별하는 것과 같은 후자는 높은 인건비와 반직관적인(그러나 중요한) 상호 작용을 놓칠 위험이 있습니다.
- 이러한 factorization 모델에서 유용한 기능 상호 작용을 미리 식별할 수 있다면 모델은 불필요한 기능 상호 작용을 처리할 필요 없이 학습에 집중할 수 있습니다. 쓸모없거나 심지어 해로운 상호작용을 제거함으로써 우리는 감소된 계산 비용으로 모델이 더 잘 수행될 것으로 기대합니다.
- 이 연구에서는 어떤 기능 상호 작용이 필수적인지 자동으로 학습하기 위해 각 기능 상호 작용에 대한 게이트(열린 상태 또는 닫힌 상태)를 도입하여 출력을 다음 계층으로 전달해야 하는지 여부를 제어합니다.
- 이전 작업에서는 문 상태가 전문가 지식에 의해 미리 지정되거나, 모두 열린 상태로 설정되었다. 데이터 기반 관점에서 게이트의 열림 여부는 최종 예측에 대한 각 기능 상호 작용의 기여도에 따라 달라집니다.
- 명백하게, 기여도가 거의 없는 사람들은 모델 학습에 추가 노이즈를 도입하는 것을 방지하기 위해 폐쇄되어야 합니다.
- 그러나 검색할 엄청나게 거대한 공간에 직면해 있기 때문에 모델 성능을 위한 최적의 열린 게이트 세트를 찾는 것은 NP-Hard 문제입니다.
- 따라서 아래에서 어떻게 이 문제를 푸는지 설명
Approach 개요
- 신경 아키텍처 검색을 위한 최근 작업 DARTS에서 영감을 받아 Factorization 모델에서 저차 및 고차 기능 상호 작용을 자동 선택하기 위한 2단계 방법 AutoFIS를 제안합니다.
- 검색 단계(Search Stage) : 후보 기능 상호 작용의 개별 집합을 검색하는 대신 아키텍처 매개 변수 집합(각 기능 상호 작용에 대해 하나씩)을 도입하여 선택을 연속적으로 완화하여 각 기능 상호 작용의 상대적 중요성을 경사하강법으로 학습할 수 있습니다.
- 아키텍처 매개변수는 GRDA 옵티마이저(희소 솔루션을 생성하기 쉬운 옵티마이저)에 의해 신경망 가중치와 함께 최적화되어 교육 프로세스가 중요하지 않은 기능 상호 작용(아키텍처 매개변수로 0 값 사용)을 자동으로 포기하고 중요한 것들을 유지할 수 있습니다.
- 재학습 단계(Re-train Stage) : 아키텍처 매개변수의 0이 아닌 값과의 기능 상호작용을 선택하고 선택한 상호작용으로 모델을 재학습하면서, 아키텍처 매개변수를 상호작용 중요도 지표 대신 attention unit으로 유지합니다.
- 성능 : 3개의 대규모 데이터 세트(2개는 공개 벤치마크이고 다른 하나는 비공개)에 대해 광범위한 실험이 수행됩니다. 실험 결과는 AutoFIS가 모든 데이터 세트에서 Factorization 모델의 CTR 예측 성능을 크게 향상시킬 수 있음을 보여줍니다. AutoFIS는 약 50%-80% 2차 기능 상호 작용을 제거할 수 있으므로 원래 모델은 항상 효율성 향상을 달성할 수 있습니다. 또한 각 3차 기능 상호 작용의 중요성을 학습하여 3차 상호 작용 선택에 AutoFIS를 적용합니다. 실험 결과에 따르면 3차 상호작용의 약 1%–10%를 선택하면 많은 계산 비용을 도입하지 않고도 Factorization 모델의 AUC를 0.1%–0.2% 향상시킬 수 있습니다.
Contribution
(1) 우리는 Factorization 모델을 훈련할 때 중복된 기능 상호작용을 제거하는 것이 유익하다는 것을 경험적으로 확인합니다.
(2) Factorization 모델에서 중요한 저차 및 고차 기능 상호작용을 자동으로 선택하기 위해 2단계 알고리즘 AutoFIS를 제안합니다. 검색 단계(Search Stage)에서 AutoFIS는 하나의 전체 교육 프로세스 내에서 아키텍처 매개변수를 통해 각 기능 상호 작용의 상대적 중요성을 학습할 수 있습니다. 재 훈련 단계(Re-train Stage)에서 중요하지 않은 상호 작용이 제거된 상태에서 결과 신경망을 다시 훈련하면서 아키텍처 매개 변수를 모델 학습을 돕기 위한 attention unit으로 유지합니다.
(3) 3개의 대규모 데이터 세트에 대한 오프라인 실험은 Factorization 모델에서 AutoFIS의 우수한 성능을 보여줍니다. 또한 AutoFIS는 많은 계산 비용을 도입하지 않고도 기존 모델의 성능을 향상시키기 위해 중요한 고차 기능 상호 작용 세트를 찾을 수 있습니다. 10일 간의 온라인 A/B 테스트에 따르면 AutoFIS는 CTR 및 CVR 측면에서 DeepFM 모델을 평균 약 20% 향상시킵니다.
2. Related Works
CTR 예측은 일반적으로 이진 분류 문제로 공식화됩니다. 이 섹션에서는 CTR 예측을 위한 Factorization모델과 추천 시스템을 위한 AutoML 모델을 간략하게 검토합니다.
Factorization 모델 검토
- Factorization Machine(FM) : 각 피쳐를 저차원 벡터로 투영하고 희소 데이터에 대해 잘 작동하는 내부곱에 의한 피쳐 상호작용을 모델로 합니다.
- FFM(Field-Aware Factorization Machine) : 각 피쳐가 다른 필드의 피쳐와 상호 작용하는 다중 벡터 표현을 가질 수 있도록 합니다.
- 최근 딥 러닝 모델은 일부 공개 벤치마크에서 최첨단 성능을 달성했습니다. Attention FM, Neural FM과 같은 여러 모델은 MLP를 사용하여 FM을 개선합니다.
- Wide & Deep : 인공 기능(사람이 중요 기능 엄선)에 대한 Wide 모델과 raw 기능에 대한 Deep 모델을 공동으로 훈련합니다.
- DeepFM : FM 레이어를 사용하여 Wide & Deep에서 Wide 파트를 대체합니다.
- PNN(Product-based NeuralNetwork) : MLP를 사용하여 FM 레이어 및 피쳐 임베딩의 상호 작용을 모델링
- PIN : 네트워크 내 네트워크 아키텍처를 도입하여 PNN 및 DeepFM의 단순한 내부 제품 작업보다는 하위 네트워크와의 쌍별 피쳐 상호 작용을 모델링합니다.
- 기존의 모든 Factorization 모델은 쓸모없고 시끄러운 많은 상호 작용을 포함하는 모든 2차 기능 상호 작용을 단순히 열거합니다.
- GBDT(Gradient Boosting Decision Tree) : 결정 트리 알고리즘을 사용하여 엔지니어링 및 검색 상호 작용을 특징으로 하는 방법입니다. 그런 다음 변환된 기능 상호 작용을 로지스틱 회귀 또는 FFM에 입력할 수 있습니다. 실제로 트리 모델은 연속 데이터에 더 적합하지만 범주형 기능의 사용률이 낮기 때문에 추천 시스템의 고차원 범주형 데이터에는 적합하지 않습니다
AutoML 모델 검토
- AutoCross : 효과적인 상호 작용을 식별하기 위해 후보 기능의 많은 하위 집합을 검색하도록 제안됩니다. 이를 위해서는 선택한 기능 상호 작용을 평가하기 위해 전체 모델을 훈련해야 하지만 후보 세트는 엄청나게 많습니다.
따라서 AutoCross는 근사의 두 가지 측면에서 가속합니다.
- 트리 구조에서 beam 검색을 통해 local optimum의 특징 집합을 greedy하게 구성하고
- 필드 인식 로지스틱 회귀를 통해 새로 생성된 특징 집합을 평가합니다.
이러한 두 가지 근사값으로 인해 AutoCross에서 추출된 고차 피쳐 상호 작용은 심층 모델에 유용하지 않을 수 있습니다. AutoCross에 비해 제안된 AutoFIS는 모든 기능 상호 작용의 중요성을 평가하기 위해 검색 단계를 한 번만 수행하면 되므로 훨씬 더 효율적입니다. 또한 학습된 유용한 상호 작용은 이 딥 모델에서 직접 학습되고 평가되므로 딥 모델을 개선합니다.
- 최근에는 DARTS[19]와 같은 원샷 아키텍처 검색 방법이 네트워크 아키텍처를 효율적으로 검색하기 위해 가장 널리 사용되는 NAS(Neural Architecture Search) 알고리즘이 되었습니다[1]. 추천 시스템에서 이러한 방법은 협업 필터링 모델에 대한 적절한 상호 작용 기능을 검색하는 데 사용됩니다[25]. [25]의 모델은 기능 상호 작용에 대한 적절한 상호 작용 기능을 식별하는 데 중점을 두는 반면 우리 모델은 중요한 기능 상호 작용을 검색하고 유지하는 데 중점을 둡니다. 신경 아키텍처 검색을 위한 최근 작업 DARTS에서 영감을 받아 아키텍처 매개변수를 통합하여 효과적인 피쳐 상호 작용을 검색하는 문제를 연속 검색 문제로 공식화합니다. 아키텍처 매개변수와 모델 가중치를 교대로 반복적으로 최적화하기 위해 2단계 최적화를 사용하는 DARTS와 달리 우리는 1단계 최적화를 사용하여 모든 데이터를 훈련 세트로 사용하여 이 두 가지 유형의 매개변수를 함께 훈련합니다. 3.2절에서 이론적으로 차이점을 분석하고 실험 섹션에서 성능을 비교합니다.
3. Method
In this section, we describe the proposed AutoFIS, an algorithm to select important feature interactions in factorization models automatically.
3.1 Factorization Model (Base Model)
Factorization Model
- 정의 3.1.Facotrization Model은 내적 또는 신경망과 같은 일부 작업에 의해 서로 다른 기능의 여러 임베딩 상호 작용을 실수로 모델링하는 모델입니다.
- FM, DeepFM 및 IPNN을 인스턴스로 사용하여 알고리즘을 공식화하고 다양한 데이터 세트의 성능을 탐색합니다.
Feature Embedding Layer
- 대부분의 CTR 예측 작업에서 데이터는 다중 필드 범주 형식으로 수집됩니다. 일반적인 데이터 전처리는 one-hot 또는 multi-hot 인코딩을 통해 각 데이터 인스턴스를 고차원 희소 벡터로 변환하는 것입니다. 필드는 다변수인 경우에만 멀티 핫 인코딩 벡터로 표현됩니다.
- 데이터 인스턴스는 x = [x1, x2, … , xm]으로 나타낼 수 있습니다. 여기서 𝑚는 필드 수이고 𝒙𝑖는 𝑖 번째 필드의 원-핫 또는 멀티-핫 인코딩 벡터입니다.
-
특징 임베딩 레이어는 e𝑖 = 𝑉𝑖x𝑖와 같이 인코딩 벡터를 저차원 벡터로 변환하는 데 사용됩니다. 여기서 𝑉𝑖는 행렬, 𝑛𝑖는 𝑖 번째 필드의 특징 값 수, 𝑑는 저차원 벡터의 차원입니다.
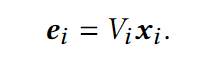
Feature Interaction Layer
-
특성을 저차원 공간으로 변환한 후(임베딩 레이어에서) 특성 상호작용 레이어를 사용하여 이러한 공간에서 특성 상호작용을 모델링할 수 있습니다. 먼저, pairwise기능 상호작용의 내적을 계산합니다.
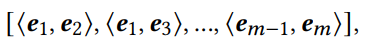
- 여기서 e𝑖는 𝑖- th 필드 ⟨·, ·⟩는 두 벡터의 내적입니다
-
FM 및 DeepFM 모델에서 기능 상호 작용 계층의 출력은
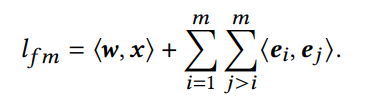
여기에서 모든 기능 상호 작용은 동일한 기여로 다음 레이어로 전달됩니다. 섹션 1에서 지적했다싶이, 그리고 섹션 4에서 확인할 사항인데, 모든 기능 상호 작용이 똑같이 예측되는 것은 아니며 불필요한 상호 작용은 성능을 저하시킬 수도 있습니다. 따라서 우리는 중요한 특징 상호작용을 효율적으로 선택하기 위해 AutoFIS 알고리즘을 제안한다.
-
우리의 방법이 중요한 고차 상호 작용을 식별하는 데 사용할 수 있는지 여부를 연구하기 위해 3차 상호 작용(즉, 세 필드의 조합)이 있는 피쳐 상호 작용 레이어를 식 (4)와 같이 정의합니다.
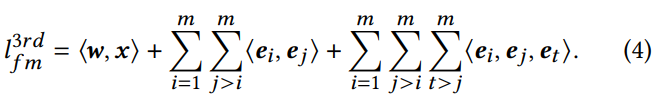
Output Layer
-
DeepFM
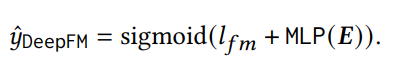
-
IPNN
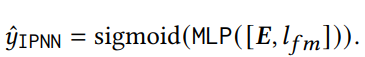
-
IPNN의 MLP 계층은 상대적인 중요성을 포착하기 위해 다양한 기능 상호 작용의 재가중치 역할을 할 수도 있습니다. 이는 IPNN이 FM 및 DeepFM보다 용량이 더 큰 이유이기도 합니다. 그러나 IPNN 공식을 사용하면 각 기능 상호 작용의 상대적 기여도에 해당하는 정확한 값을 검색할 수 없습니다. 따라서 IPNN에서 쓸모없는 기능 상호 작용은 식별되거나 삭제될 수 없으므로 모델에 추가 노이즈와 계산 비용이 발생합니다. 다음 하위 섹션과 섹션 4에서 제안된 방법 AutoFIS가 IPNN을 개선할 수 있는 방법을 보여줍니다.
Objective Function
-
FM, DeepFM 및 IPNN은 동일한 목적 함수를 공유합니다. 즉, 예측 값과 레이블의 크로스 엔트로피를 식 (9)와 같이 최소화합니다. 여기서 𝑦 ∈ {0, 1}은 레이블이고 𝑦ˆM ∈ [0, 1] 는 𝑦 = 1의 예측 확률입니다.
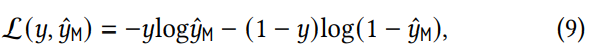
3.2 AutoFIS
AutoFIS는 모든 Factorization모델의 기능 상호 작용 계층에 적용할 수 있는 유용한 기능 상호 작용을 자동으로 선택합니다. 이 섹션에서는 작동 방식에 대해 자세히 설명합니다. AutoFIS는 탐색 단계(Search)와 재훈련(Re-Train) 단계의 두 단계로 나눌 수 있습니다. Search단계에서 AutoFIS는 유용한 기능 상호 작용을 감지합니다. Re-Train단계에서 선택된 기능 상호작용이 있는 모델은 재훈련됩니다.
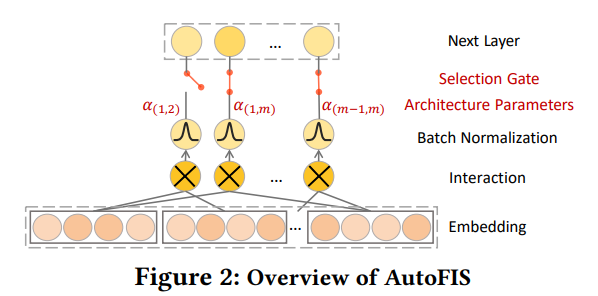
Search Stage
Architecture Parameter 𝜶
- 알고리즘의 표현을 용이하게 하기 위해 특징 상호작용 선택 여부를 제어하는 게이트 작업을 소개합니다. 열린 게이트는 특징 상호작용 선택에 해당하고 닫힌 게이트는 상호작용이 중단되는 결과를 가져옵니다. 모든 2차 특징 상호작용에 해당하는 총 게이트 수는 C^2𝑚입니다. 검색할 엄청나게 거대한 (2^C^2𝑚 ) 공간에 직면하기 때문에 무차별 대입 방식으로 최적의 열린 게이트 세트를 찾는 것은 매우 어렵습니다. → 이 작업에서 우리는 다른 관점에서 문제에 접근합니다. 이산적인 열린 게이트 세트를 검색하는 대신 아키텍처 매개변수 𝜶를 도입하여 연속적인 선택을 완화합니다. 각 기능 상호 작용의 상대적 중요성을 경사하강법을 통해 학습할 수 있습니다.. 제안된 AutoFIS의 개요는 그림 2에 나와 있습니다.
-
그래디언트 학습에 의한 이 아키텍처 선택 방식은 DARTS[19]에서 영감을 얻었습니다. 여기서 목표는 CNN(Convolutional Neural Network) 아키텍처의 후보 작업 집합에서 하나의 작업을 선택하는 것입니다. 구체적으로, 우리는 Factorization 모델(수식 3에 표시)의 상호작용 계층을 방정식(10)으로 재구성합니다.
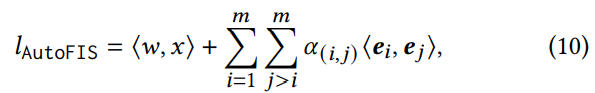
- 𝜶 = {𝛼(1,2) , · · · , 𝛼(𝑚−1,𝑚) } = 아키텍처 매개변수.
- AutoFIS의 검색 단계에서 𝛼(𝑖,𝑗) 값은 𝛼(𝑖,𝑗)이 최종 예측에 대한 각 기능 상호 작용의 상대적 기여도를 나타낼 수 있는 방식으로 학습됩니다. 그런 다음 중요하지 않은 항목(예: 𝛼(𝑖,𝑗) 값이 0)을 닫음으로 설정하여 각 기능 상호 작용의 게이트 상태를 결정할 수 있습니다.
- 즉, 탐색 단계에서 α : 최종 예측에 대한 각 기능 상호 작용의 기여도의 상대적 크기
Batch Normalization
- 전체 신경망의 관점에서 기능 상호작용의 기여도는 𝛼(𝑖,𝑗) · ⟨e𝑖 , e 𝑗⟩ (식 10)로 측정됩니다. 이 항을 ( 𝛼(𝑖, 𝑗) 𝜂 ) · (𝜂 · ⟨e𝑖 , e 𝑗⟩)로 re-scaling하여 정확히 동일한 기여를 할 수 있습니다. 여기서 𝜂는 실수입니다.
- ⟨e𝑖 , e 𝑗⟩ 의 값은 𝛼(𝑖,𝑗)와 공동으로 학습되므로 스케일의 결합(coupling)문제는 𝛼(𝑖,𝑗)의 불안정한 추정으로 이어져 𝛼(𝑖,𝑗)는 더이상 ⟨e𝑖 , e 𝑗⟩ 의 상대적 중요성을 나타내지 못합니다. 이 문제를 해결하기 위해 ⟨e𝑖 , e 𝑗⟩에 배치 정규화(BN) [12]를 적용하여 스케일링 문제를 제거(de-coupling)합니다. BN은 빠른 수렴과 더 나은 성능을 달성하기 위한 표준 접근 방식으로 심층 신경망을 훈련하여 채택되었습니다. BN이 값을 정규화하는 방식은 𝛼(𝑖,𝑗) 및 ⟨e𝑖 , e 𝑗⟩의 결합(coupling) 문제를 해결하는 효율적이고 효과적인 방법을 제공합니다.
-
기존 BN 식을 살펴보자 :
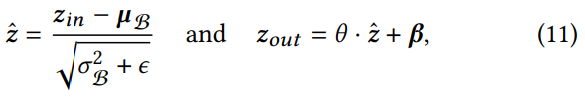
- 𝒛𝑖𝑛, 𝒛ˆ, 𝒛𝑜𝑢𝑡 : BN의 입력, 정규화 및 출력 값
- 𝝁 B, 𝜎B : 미니 배치 B에 대한 𝒛𝑖𝑛의 평균 및 표준 편차
- 𝜃 𝜷 : BN의 훈련 가능한 scale 및 shift 매개변수 매개변수
- 𝜖 : 수치적 안정성을 위한 상수
-
𝛼(𝑖,𝑗) 의 안정적인 추정을 위해 scale 및 shift 매개변수를 각각 1과 0으로 설정합니다. 각 기능 상호작용 ⟨e𝑖 , e 𝑗⟩ 에 대한 BN 연산은 방정식(12)로 계산됩니다.
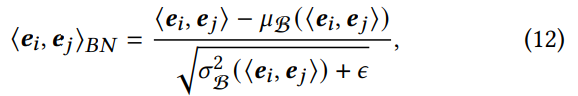
- 𝜇B 𝜎B : 미니 배치 B에서 ⟨e𝑖 , e 𝑗⟩ 의 평균과 표준편차
GRDA Optimizer
- 검색 단계에서 GRDA 옵티마이저를 사용하여 아키텍처 매개변수 𝜶를 학습하고 sparse 솔루션을 얻습니다. 중요하지 않은 기능 상호 작용(예: 0인 𝛼(𝑖,𝑗) 값)은 자동으로 폐기됩니다. 다른 매개변수는 정상적으로 Adam 옵티마이저에 의해 학습됩니다.
- GRDA 옵티마이저 : 확률적 경사하강법(SGD)이 훈련 손실에서 평평한 최소 계곡을 종종 발견한다는 사실에 비추어, 우리는 그 평평한 영역에서 또는 그 근처에서 sparse minimizer를 찾는 새로운 방향 가지치기 방법을 제안합니다. 제안된 가지치기 방법은 재교육이나 희소성 수준에 대한 전문 지식이 필요하지 않습니다. 평평한 방향을 추정하는 계산비용을 극복하기 위해 우리는 충분한 훈련 후에 작은 학습률로 방향 가지치기를 입증할 수 있는 신중하게 조정된 $\ell_1$ prozimal 기울기 알고리즘을 사용할 것을 제안합니다.(NeurIPS 2020)
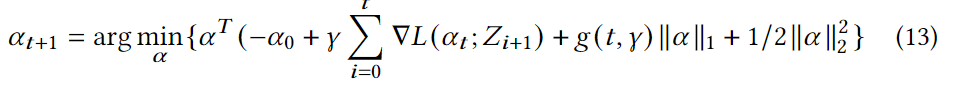
One Level Optimization
- AutoFIS의 검색 단계에서 아키텍처 매개변수 𝛼(𝑖,𝑗)를 학습하기 위해 다른 모든 네트워크 가중치 𝒗와 함께 𝜶 최적화를 제안합니다. 이것은 DARTS와 다릅니다. DARTS는 𝜶를 상위 수준의 결정 변수로 취급하고 네트워크 가중치를 하위 수준의 변수로 취급한 다음 이중 수준 최적화 알고리즘으로 최적화합니다. DARTS에서는 𝜶가 “적절한 결정”을 내릴 수 있도록 네트워크 가중치를 적절하게 학습한 경우에만 모델이 작업을 선택할 수 있다고 가정합니다. AutoFIS 공식화의 맥락에서 이것은 네트워크 가중치가 적절하게 훈련된 후에 게이트를 열거나 닫아야 하는지 여부를 결정할 수 있음을 의미하며, 이는 결정을 내리기 위해 2^C^2𝑚 모델을 완전히 훈련시키는 문제로 다시 이끕니다. 이 문제를 피하기 위해 DARTS는 단 하나의 경사 하강 단계로 네트워크 가중치의 최적 값을 근사화하고 𝜶 및 𝒗를 반복적으로 훈련할 것을 제안합니다.
-
우리는 이 근사치의 부정확성이 성능을 저하시킬 수 있다고 주장합니다. 따라서 2단계 최적화를 사용하는 대신 1단계 최적화와 함께 𝜶 및 𝒗를 함께 최적화하는 것을 제안합니다. 구체적으로, 매개변수 𝜶 및 𝒗는 식 14에 따라 𝜶 및 𝒗에 대해 내림차순으로 훈련 세트를 사용하여 경사하강법과 함께 업데이트됩니다.
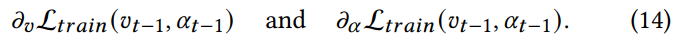
- 이 설정에서 𝜶와 𝒗는 수렴할 때까지 디자인 공간을 자유롭게 탐색할 수 있으며 𝜶는 개별 기능 상호 작용의 기여도를 학습합니다. 섹션 4에서 우리는 2레벨 최적화보다 1레벨 최적화의 우월성을 보여줄 것입니다.
Re-Train Stage
- 검색 단계의 훈련 후, 검색 단계의 아키텍처 매개변수 𝜶*에 따라 중요하지 않은 일부 상호 작용은 자동으로 폐기됩니다. G(𝑖,𝑗)를 사용하여 기능 상호작용 ⟨e𝑖, e 𝑗⟩의 게이트 상태를 나타내고 𝛼∗(𝑖,𝑗)= 0일 때 G(𝑖,𝑗)를 0으로 설정합니다. 그렇지 않으면 G(𝑖,𝑗)를 1로 설정합니다. 재학습 단계에서 이러한 중요하지 않은 기능 상호 작용의 게이트 상태는 영구적으로 닫히도록 고정됩니다.
-
이러한 중요하지 않은 상호 작용을 제거한 후 𝜶가 모델에 유지된 상태로 새 모델을 다시 학습합니다. 구체적으로, 우리는 수학식 3의 피처 상호작용 레이어를 수학식 15로 대체합니다.
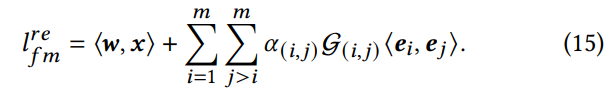
- 𝛼(𝑖,𝑗) 는 더 이상 상호 작용이 모델에 포함되어야 하는지 여부를 결정하는 지표로 사용되지 않습니다. 대신, 유지된 기능 상호 작용의 relative importance을 학습하는 아키텍처의 attention unit역할을 합니다. 이 단계에서는 기능 상호 작용을 선택할 필요가 없습니다. 따라서 모든 매개변수는 Adam 옵티마이저에 의해 학습됩니다.
4. Experiments
성능
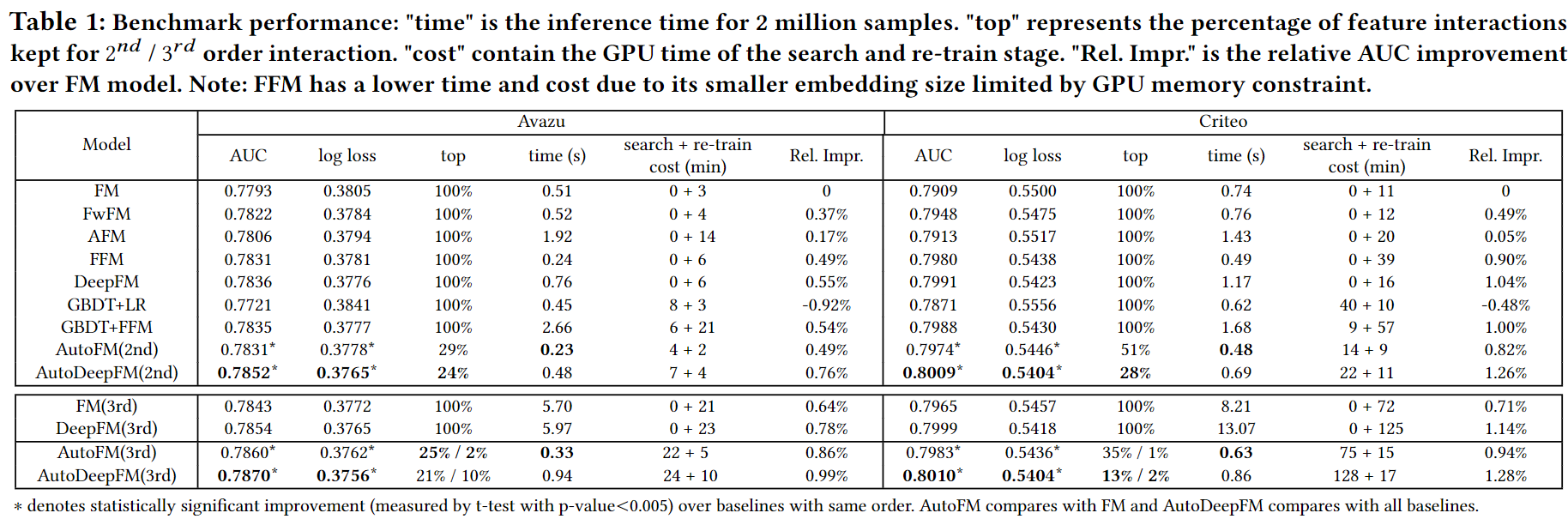
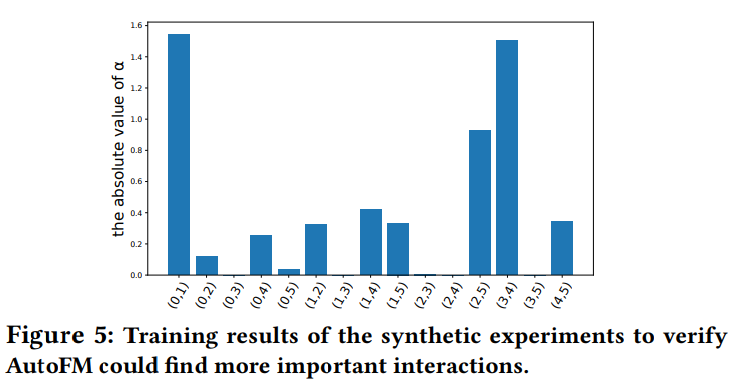
주목할 부분 : The Effectiveness of Feature Interaction Selected by AutoFIS
- RQ3: Are the interactions selected by AutoFIS really important and useful?
- 의미적인 experiments 진행
-
random한 interaction 샘플을 만들고, FM과 비교
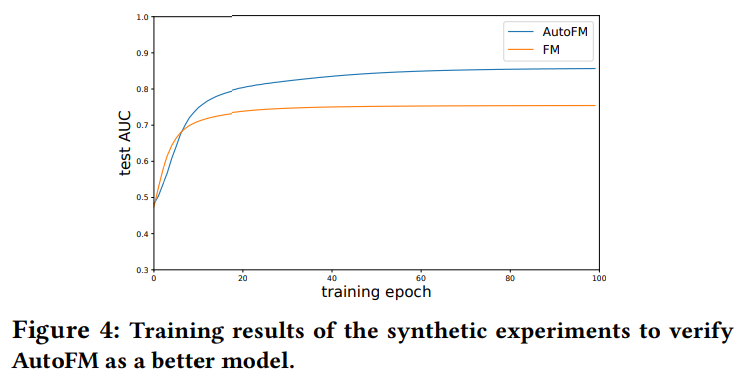
-
a값에 따라 시각화로 feature interaction 중요도 표시