[논문리뷰]DeepFM: A Factorization-Machine based Neural Networks for CTR Prediction(2017)
0. Abstract
- Click Through Rate(CTR)을 예측하는 모델이다
- Low와 High-order interactions 모두 학습할 수 있다
- Factorization Machine의 장점과 Deep Learning의 장점을 합친 모델이 DeepFM이다
- 추가 feature engineering 없이 raw feature를 그대로 사용할 수 있다 (cf. Wide & Deep)
- 벤치마크 데이터와 commercial 데이터에서 모두 실험을 완료했다.
1. Introduction (1)
- CTR : user가 추천된 항목을 click할 확률을 예측하는 문제이다.
- CTR(estimated probability)에 의해 user가 선호할 item 랭킹을 부여한다.
- Learn Implicit Feature Interaction
- App Category와 Timestamp 관계 : 음식 배달 어플은 식사시간 근처에 다운로드가 많다
- User gender와 Age 관계 : 10대 남자 청소년들은 슈팅과 RPG게임을 선호한다.
- 숨겨진 관계: 맥주와 기저귀를 함께 구매하는 사람들이 많다.
→ low와 high-order feature interaction을 모두 고려해야 한다.
→ Explicit과 Implicit features를 모두 모델링할 수 있다.
1. Introduction (2) 현재까지의 추천알고리즘 연구
- Generalized Linear Model(ex. FTRL:Follow the Regularized Leader) (2013)
- 당시 성능은 좋은 모델이었으나, High-order feature interaction을 반영하기 어렵다.
- Factorization Machine (2010)
- Latent vector간의 내적을 통해 pairwise feature interaction 모델링한다.
- Low와 high-order 모두 모델링이 가능하지만, high-order의 경우 complexity 증가
- CNN and RNN for CTR Prediction(2015)
- CNN-based는 주변 feature에 집중하지만, RNN-based는 sequential해서 더 적합하다
- Factorization-machine supported Neural Network(FNN), Product-based Neural Network (2016)
- Neural Network 기반으로 high-order 가능하지만 low-order는 부족하다
- Pre-trained FM 성능에 의존할 수 있다.
- Wide & Deep (2016)
- Low와 high-order 모두 가능하지만, wide component에 feature engineering이 필요하다
1. Contributions
- DeepFM이라는 모델 구조를 제안한다
- Low-order는 FM, High-order는 DNN
- End-to-end 학습 가능
- DeepFM은 다른 비슷한 모델보다 더 효율적으로 학습할 수 있다.
- Input과 embedding vector를 share한다.
- DeepFM은 benchmark와 commercial 데이터의 CTR prediction에서의 의미있는 성능향상을 이루었다.
2. Our Approach
데이터 구조 및 목표
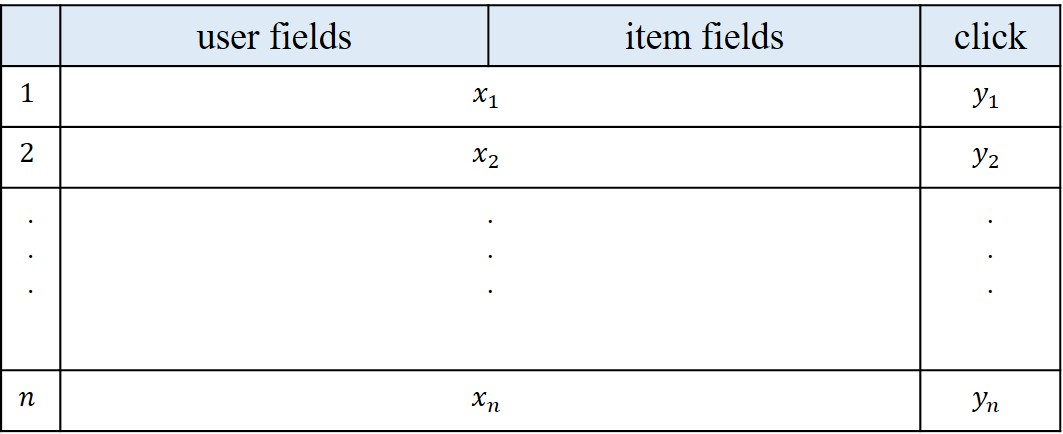
- 총 n개의 데이터가 있다고 할 때, 각 row는 user와 item 정보를 담고 있는 x와 특정 아이템 클릭여부를 나타내는 y로 이루어져 있다.
- 먼저 x는 m개의 필드로 이뤄져 있으며 각 필드는 다양한 정보를 담고 있다. 예를 들어 user 필드에는 user의 id, 성별, 나이 등의 정보가, item 필드에는 특정 item의 구매 정보 등이 포함된다. 각 필드에는 카테고리 피처일 경우 one-hot 벡터로, 연속적인 피처일 경우 해당 값을 그대로 사용할 수 있다. 일반적으로 x는 굉장히 sparse 하며 고차원이다.
- y 는 user의 특정 item에 대한 클릭여부를 나타낸다. 만약 user가 특정 item을 클릭 했을 경우 y=1, 클릭하지 않았을 경우 y=0이 된다.
- 위와 같은 데이터 구조를 고려할 때, DeepFM의 목표는 x 가 주어졌을 때, user가 특정 item을 클릭할 확률을 예측하는 것이 되겠다.
2. 전체 아키텍쳐
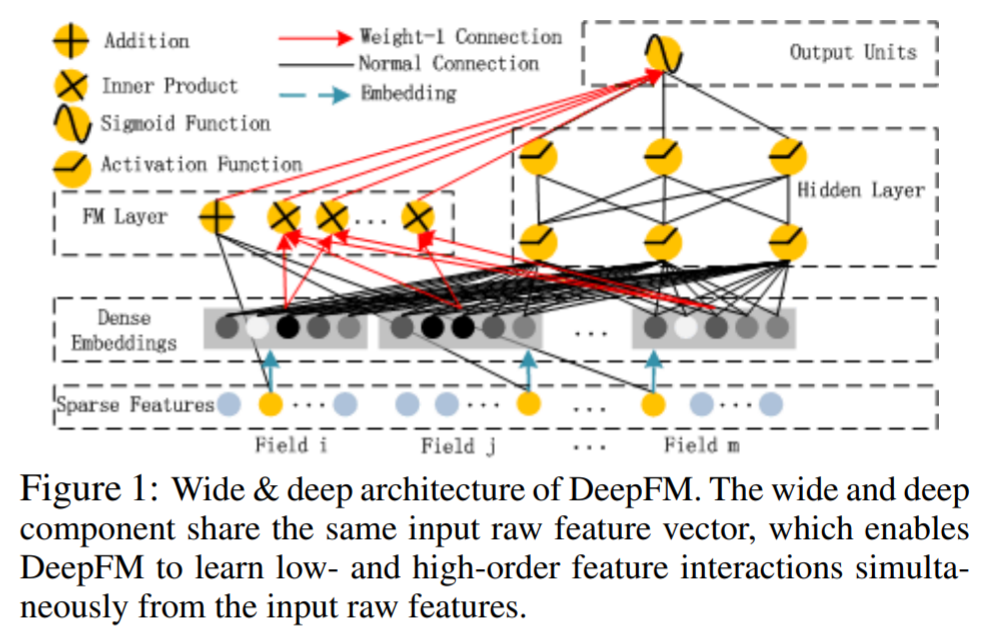
- input : Input의 경우 주목할 만한 특징은 FM layer와 Hidden layer가 같은 embedding 벡터를 공유한다는 점이다. 이는 앞서 Wide & Deep 모델과의 차별점이다. Sparse features의 노란색부분은 embedding vector(x_field_i w_i = V_i)에 해당된다. 정리하자면 위 그림의 Sparse Features 부분에서, 각 필드의 노란색 부분에 해당하는 embedding 벡터를 FM과 DNN 이 모두 사용하는 것이 특징이다.
- output : output 같은 경우는 아래 처럼 두 모델이 각각 내놓은 예측치를 더한 값을 최종 결과로 사용한다.
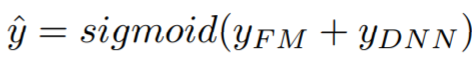
2. FM Component
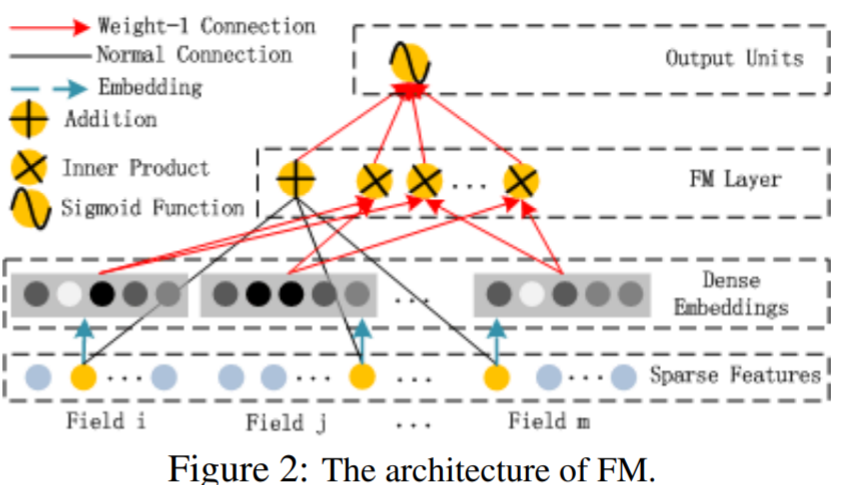
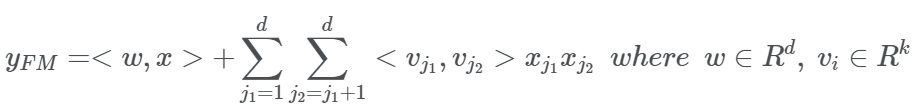
- low-order feature interaction을 포착하는 FM 모델
- Embedding vector의 내적을 order-2의 가중치로 사용한다는 것이 포인트.
- FM 모델은 order-1 interaction을 포착하는 텀과, order-2 interaction을 포착하는 텀으로 나눠진다. 특징은 order-2 interaction 텀의 가중치를 위에서 설명한 embedding 벡터들의 내적으로 사용한다는 것이다. 예를 들어 10대와 20대 피처의 interaction 가중치는 10대, 20대에 해당하는 embedding 벡터들의 내적이 되는 것이다.
2. Deep Component
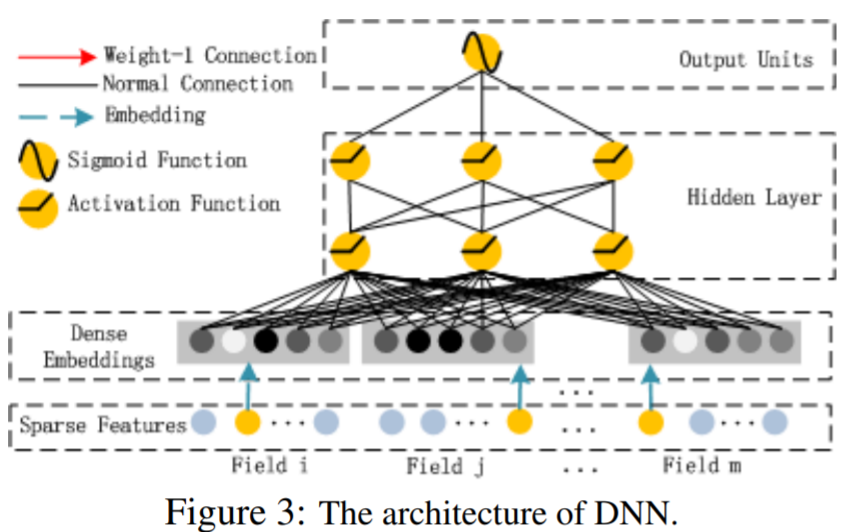
- high-order feature interaction을 포착하는 DNN 모델
- 모든 embedding vector를 합친 것(Sparse Features의 노란색)이 input이 된다.
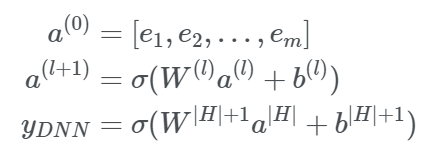
- FM 모델에서는 embedding 벡터가 interaction 텀의 가중치의 역할을 했다면, DNN 모델에서는 input으로 사용된다. 즉 ei(=v), i=1,..,m가 field i의 노란색 부분에 해당하는 embedding 벡터라 할때, 이런 벡터들을 모두 합친 a(0) 가 모델의 input이 되는 것이다. 나머지는 익히 알고있는 DNN의 구조와 동일하며, H 개의 층을 모두 통과해 나온 aH 에 output의 차원을 맞춰준 후 sigmoid 함수를 통과한 값이 최종 결과가 된다.
2. Relationship with the other Neural Networks
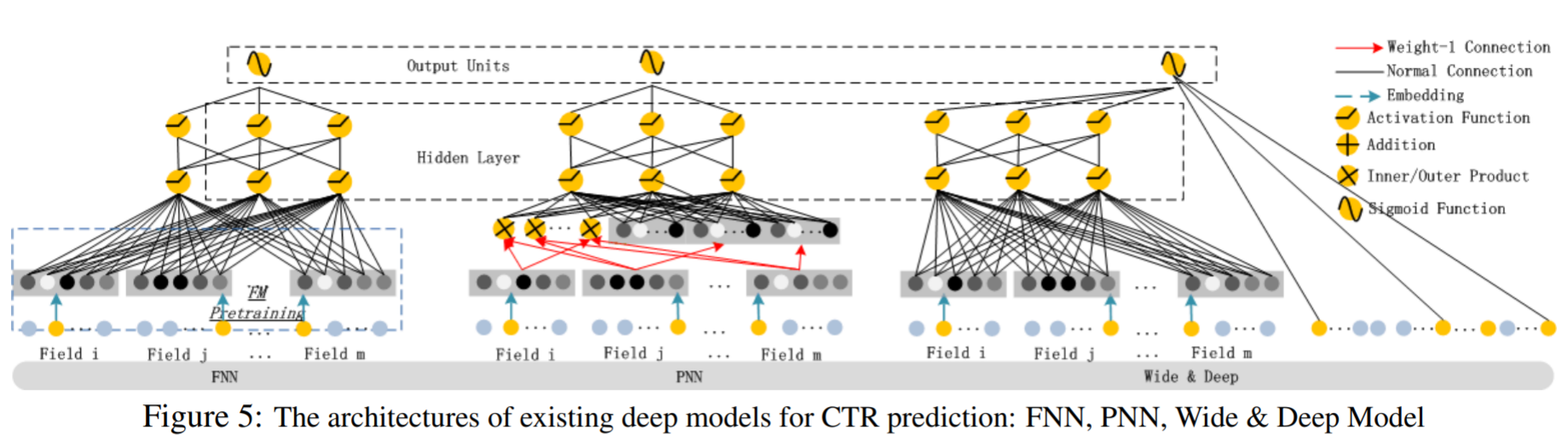
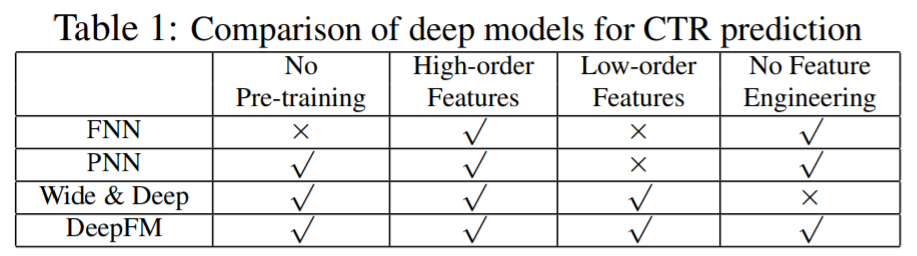
- DeepFM는 low-order, high-order interaction이 모두 표현 가능하며, Wide & Deep 모델과 달리 별도의 feature engineering 이 필요없다. 또한 FNN는 FM을 미리 훈련시킨후 이를 DNN 가중치 초기화시 사용했다면, DeepFM은 FM을 DNN과 함께 훈련시키는 방식이므로 FM의 성능에 좌우되지 않는 장점이 있다.
3. Experiments
- Criteo Dataset
- 45 million users’ click records
- 13 연속형변수, 26 범주형변수
- 90% training, 10% testing
- Company* Dataset
- 7일간의 users’ click records Company App Store
- 다음 1일을 testing에 씀
- 1 billion records
- App features (identification, category)
- User features (user’s downloaded apps)
- Context features(operation time)
- Evaluation Metrics
- AUC
- Logloss(Cross Entropy)
3. Efficiency Comparison
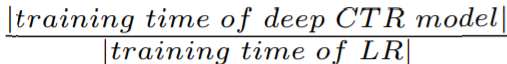
- Linear Model 대비 각 모델이 학습에 걸린 시간 비교
- FNN은 pre-training에 시간을 많이 쏟는다
- IPNN과 OPNN은 hidden layer에서 inner product를 하면서 시간이 매우 오래걸린다
Conclusions
- DeepFM
- deep component와 FM component를 합쳐서 학습한다
- Pre-training이 필요하지 않다
- High와 low-order feature interactions 둘 다 모델링한다
- Input과 embedding vector를 share한다.
- From experiments
- CTR task에서 더 좋은 성능을 얻을 수 있다
- 다른 SOTA 모델보다 AUC와 LogLoss에서 성능이 뛰어나다
- DeepFM이 가장 efficient한 모델이다.
