[논문구현]Attentional factorization machines: Learning the weight of feature interactions via attention networks(2017)
AFM
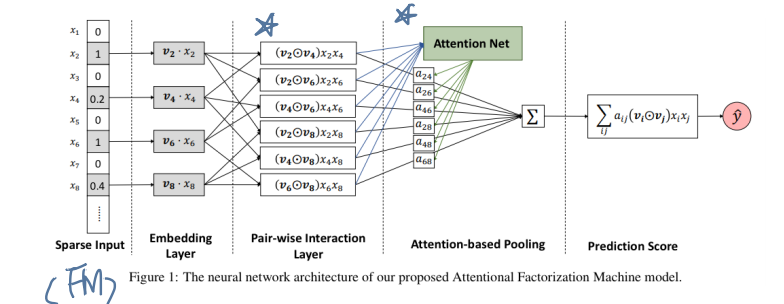
Data Load(adult>=50k) : Sparse Input
- adult.data : 성인 연봉이 50k 달러가 넘을것인지 분류하는 데이터
- 출처 : UCI (https://archive.ics.uci.edu/ml/datasets/adult)
from google.colab import drive
drive.mount('/content/drive')
data_path = "/content/drive/MyDrive/capstone/data/adult.data"
ALL_FIELDS = ['age', 'workclass', 'fnlwgt', 'education', 'education-num',
'marital-status', 'occupation', 'relationship', 'race',
'sex', 'capital-gain', 'capital-loss', 'hours-per-week', 'country']
CONT_FIELDS = ['age', 'fnlwgt', 'education-num',
'capital-gain', 'capital-loss', 'hours-per-week']
CAT_FIELDS = list(set(ALL_FIELDS).difference(CONT_FIELDS))
IS_BIN = True # 연속형 변수도 구간화할 것인가?
NUM_BIN = 10
dataset_label = 'adult_'
import tensorflow as tf
import numpy as np
import os
import random
SEED = 1234
def seed_everything(seed: int = 1234):
random.seed(seed)
np.random.seed(seed)
os.environ["PYTHONHASHSEED"] = str(seed)
tf.random.set_seed(seed)
seed_everything(SEED)
## Data Load & Preprocess
import numpy as np
import pandas as pd
from time import perf_counter
import tensorflow as tf
from sklearn.model_selection import train_test_split
from itertools import repeat
from sklearn.preprocessing import MinMaxScaler
import os
from numpy import count_nonzero
def get_sparsity(A):
sparsity = 1.0 - count_nonzero(A) / A.size
return sparsity
def get_modified_data(X, all_fields, continuous_fields, categorical_fields, is_bin=False):
field_dict = dict()
field_index = []
X_modified = pd.DataFrame()
for index, col in enumerate(X.columns):
if col not in all_fields:
print("{} not included: Check your column list".format(col))
raise ValueError
if col in continuous_fields:
scaler = MinMaxScaler()
# 연속형 변수도 구간화 할 것인가?
if is_bin:
X_bin = pd.cut(scaler.fit_transform(X[[col]]).reshape(-1, ), NUM_BIN, labels=False)
X_bin = pd.Series(X_bin).astype('str')
X_bin_col = pd.get_dummies(X_bin, prefix=col, prefix_sep='-')
field_dict[index] = list(X_bin_col.columns)
field_index.extend(repeat(index, X_bin_col.shape[1]))
X_modified = pd.concat([X_modified, X_bin_col], axis=1)
else:
X_cont_col = pd.DataFrame(scaler.fit_transform(X[[col]]), columns=[col])
field_dict[index] = col
field_index.append(index)
X_modified = pd.concat([X_modified, X_cont_col], axis=1)
if col in categorical_fields:
X_cat_col = pd.get_dummies(X[col], prefix=col, prefix_sep='-')
field_dict[index] = list(X_cat_col.columns)
field_index.extend(repeat(index, X_cat_col.shape[1]))
X_modified = pd.concat([X_modified, X_cat_col], axis=1)
print('Data Prepared...')
print('X shape: {}'.format(X_modified.shape))
print('# of Feature: {}'.format(len(field_index)))
print('# of Field: {}'.format(len(field_dict)))
return field_dict, field_index, X_modified
def get_data_dfm():
file = pd.read_csv(data_path, header=None, engine='python')
X = file.loc[:, 0:13]
Y = file.loc[:, 14].map({' <=50K': 0, ' >50K': 1})
X.columns = ALL_FIELDS
field_dict, field_index, X_modified = \
get_modified_data(X, ALL_FIELDS, CONT_FIELDS, CAT_FIELDS, IS_BIN)
X_numpy = tf.cast(X_modified.values, tf.float32).numpy()
sparsity = get_sparsity(X_numpy)
print('Data Sparsity : {:.4f}'.format(sparsity))
X_train, X_test, Y_train, Y_test = train_test_split(X_modified, Y, test_size=0.2, stratify=Y, shuffle=True, random_state=SEED)
X_train, X_val, Y_train, Y_val = train_test_split(X_train, Y_train, test_size=0.25, stratify=Y_train, shuffle=True) # 0.25 x 0.8 = 0.2
train_ds = tf.data.Dataset.from_tensor_slices(
(tf.cast(X_train.values, tf.float32), tf.cast(Y_train, tf.float32))) \
.shuffle(30000).batch(data_batch_size)
test_ds = tf.data.Dataset.from_tensor_slices(
(tf.cast(X_test.values, tf.float32), tf.cast(Y_test, tf.float32))) \
.shuffle(10000).batch(data_batch_size)
val_ds = tf.data.Dataset.from_tensor_slices(
(tf.cast(X_val.values, tf.float32).numpy(), tf.cast(Y_val, tf.float32).numpy())) \
.shuffle(10000).batch(data_batch_size)
return train_ds, val_ds, test_ds, field_dict, field_index
## Load Data
X_tr, y_tr, X_val, y_val, X_te, y_te, field_dict, field_index = get_data_dfm()
model_save_path = '/content/drive/MyDrive/capstone/result/adult/'
Data Prepared...
X shape: (32561, 157)
# of Feature: 157
# of Field: 14
Data Sparsity : 0.9108
Embedding Layer
data_batch_size = 1024
HIDDEN_SIZE = 150
DROPOUT_RATE = 0.2
import tensorflow as tf
import numpy as np
class Embedding_layer(tf.keras.layers.Layer):
def __init__(self, num_field, num_feature, num_cont, embedding_size):
super(Embedding_layer, self).__init__()
self.embedding_size = embedding_size # k: 임베딩 벡터의 차원(크기)
self.num_field = num_field # m: 인코딩 이전 feature 수
self.num_feature = num_feature # p: 인코딩 이후 feature 수, m <= p
self.num_cont = num_cont # 연속형 field 수
self.num_cat = num_field - num_cont # 범주형 field 수
# Parameters
self.V = tf.Variable(tf.random.normal(shape=(num_feature, embedding_size),
mean=0.0, stddev=0.01), name='V')
def call(self, inputs):
# inputs: (None, p, k), embeds: (None, m, k)
batch_size = inputs.shape[0]
# 원핫인코딩으로 생성된 0을 제외한 값에 True를 부여한 mask(np.array): (None, m)
# indices: 그 mask의 indices
cont_mask = np.full(shape=(batch_size, self.num_cont), fill_value=True)
cat_mask = tf.not_equal(inputs[:, self.num_cont:], 0.0).numpy()
mask = np.concatenate([cont_mask, cat_mask], axis=1)
_, flatten_indices = np.where(mask == True)
indices = flatten_indices.reshape((batch_size, self.num_field))
# embedding_matrix: (None, m, k)
embedding_matrix = tf.nn.embedding_lookup(params=self.V, ids=indices.tolist())
# masked_inputs: (None, m, 1)
masked_inputs = tf.reshape(tf.boolean_mask(inputs, mask),
[batch_size, self.num_field, 1])
masked_inputs = tf.multiply(masked_inputs, embedding_matrix) # (None, m, k)
return masked_inputs
Pair-wise Interaction Layer
class Pairwise_Interaction_Layer(tf.keras.layers.Layer):
def __init__(self, num_field, num_feature, embedding_size):
super(Pairwise_Interaction_Layer, self).__init__()
self.embedding_size = embedding_size # k: 임베딩 벡터의 차원(크기)
self.num_field = num_field # m: 인코딩 이전 feature 수
self.num_feature = num_feature # p: 인코딩 이후 feature 수, m <= p
masks = tf.convert_to_tensor(MASKS) # (num_field**2)
masks = tf.expand_dims(masks, -1) # (num_field**2, 1)
masks = tf.tile(masks, [1, embedding_size]) # (num_field**2, embedding_size)
self.masks = tf.expand_dims(masks, 0) # (1, num_field**2, embedding_size)
def call(self, inputs):
batch_size = inputs.shape[0]
# a, b shape: (batch_size, num_field^2, embedding_size)
a = tf.expand_dims(inputs, 2)
a = tf.tile(a, [1, 1, self.num_field, 1])
a = tf.reshape(a, [batch_size, self.num_field**2, self.embedding_size])
b = tf.tile(inputs, [1, self.num_field, 1])
# ab, mask_tensor: (batch_size, num_field^2, embedding_size)
ab = tf.multiply(a, b)
mask_tensor = tf.tile(self.masks, [batch_size, 1, 1])
# pairwise_interactions: (batch_size, num_field C 2, embedding_size)
pairwise_interactions = tf.reshape(tf.boolean_mask(ab, mask_tensor),
[batch_size, -1, self.embedding_size])
return pairwise_interactions
Attention-based Pooling
class Attention_Pooling_Layer(tf.keras.layers.Layer):
def __init__(self, embedding_size, hidden_size):
super(Attention_Pooling_Layer, self).__init__()
self.embedding_size = embedding_size # k: 임베딩 벡터의 차원(크기)
# Parameters
self.h = tf.Variable(tf.random.normal(shape=(1, hidden_size),
mean=0.0, stddev=0.1), name='h')
self.W = tf.Variable(tf.random.normal(shape=(hidden_size, embedding_size),
mean=0.0, stddev=0.1), name='W_attention')
self.b = tf.Variable(tf.zeros(shape=(hidden_size, 1)))
def call(self, inputs):
# 조합 수 = combinations(num_feauture, 2)
# inputs: (None, 조합 수, embedding_size)
# --> (전치 후) (None, embedding_size, 조합 수)
inputs = tf.transpose(inputs, [0, 2, 1])
# e: (None, 조합 수, 1)
e = tf.matmul(self.h, tf.nn.relu(tf.matmul(self.W, inputs) + self.b))
e = tf.transpose(e, [0, 2, 1])
# Attention Score 산출
attention_score = tf.nn.softmax(e)
return attention_score
# Model 정의
tf.keras.backend.set_floatx('float32')
class AFM(tf.keras.Model):
def __init__(self, num_field, num_feature, num_cont, embedding_size, hidden_size):
super(AFM, self).__init__()
self.embedding_size = embedding_size # k: 임베딩 벡터의 차원(크기)
self.num_field = num_field # m: 인코딩 이전 feature 수
self.num_feature = num_feature # p: 인코딩 이후 feature 수, m <= p
self.num_cont = num_cont # 연속형 field 수
self.hidden_size = hidden_size # Attention Pooling Layer Hidden Unit 수
self.embedding_layer = Embedding_layer(num_field, num_feature,
num_cont, embedding_size)
self.pairwise_interaction_layer = Pairwise_Interaction_Layer(
num_field, num_feature, embedding_size)
self.attention_pooling_layer = Attention_Pooling_Layer(embedding_size, hidden_size)
# Parameters
self.w_0 = tf.Variable(tf.zeros([1]))
self.w = tf.Variable(tf.zeros([num_feature]))
self.p = tf.Variable(tf.random.normal(shape=(embedding_size, 1),
mean=0.0, stddev=0.1))
self.dropout = tf.keras.layers.Dropout(rate=DROPOUT_RATE)
def __repr__(self):
return "AFM Model: embedding{}, hidden{}".format(self.embedding_size, self.hidden_size)
def call(self, inputs):
# 1) Linear Term: (None, )
linear_terms = self.w_0 + tf.reduce_sum(tf.multiply(self.w, inputs), 1)
# 2) Interaction Term
masked_inputs = self.embedding_layer(inputs)
pairwise_interactions = self.pairwise_interaction_layer(masked_inputs)
# Dropout and Attention Score
pairwise_interactions = self.dropout(pairwise_interactions)
attention_score = self.attention_pooling_layer(pairwise_interactions)
# (None, 조합 수, embedding_size)
attention_interactions = tf.multiply(pairwise_interactions, attention_score)
# (None, embedding_size)
final_interactions = tf.reduce_sum(attention_interactions, 1)
# 3) Final: (None, )
y_pred = linear_terms + tf.squeeze(tf.matmul(final_interactions, self.p), 1)
y_pred = tf.nn.sigmoid(y_pred)
return y_pred
실행
import numpy as np
import pandas as pd
from time import perf_counter
import tensorflow as tf
from sklearn.model_selection import train_test_split
from tensorflow.keras.metrics import BinaryAccuracy, AUC, Precision, Recall
from sklearn.preprocessing import MinMaxScaler
from itertools import repeat
import numpy as np
import pandas as pd
from time import perf_counter
import tensorflow as tf
from sklearn.model_selection import train_test_split
from tensorflow.keras.metrics import BinaryAccuracy, AUC
def train_on_batch(model, optimizer, acc, auc, inputs, targets):
with tf.GradientTape() as tape:
y_pred = model(inputs)
loss = tf.keras.losses.binary_crossentropy(from_logits=False, y_true=targets, y_pred=y_pred)
grads = tape.gradient(target=loss, sources=model.trainable_variables)
# apply_gradients()를 통해 processed gradients를 적용함
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# accuracy & auc
acc.update_state(targets, y_pred)
auc.update_state(targets, y_pred)
return loss
def get_mask(num_field):
masks = []
for i in range(num_field):
flag = 1 + i
masks.extend([False]*(flag))
masks.extend([True]*(num_field - flag))
return masks
# 반복 학습 함수
def run_afm(epochs):
train_ds, val_ds, test_ds, field_dict, field_index = get_data_dfm()
num_field=len(field_dict)
global MASKS
MASKS = get_mask(num_field)
# def __init__(self, num_field, num_feature, num_cont, embedding_size, hidden_size):
model = AFM(embedding_size=EMBEDDING_SIZE, num_feature=len(field_index),
num_field=len(field_dict), num_cont=0, hidden_size=HIDDEN_SIZE)
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
print("Start Training: Batch Size: {}, Embedding Size: {}".format(data_batch_size, EMBEDDING_SIZE))
start = perf_counter()
for i in range(epochs):
acc = BinaryAccuracy()
auc = AUC(threshold=[threshold])
loss_history = []
for x, y in train_ds:
loss = train_on_batch(model, optimizer, acc, auc, x, y)
loss_history.append(loss)
print("Epoch {:03d}: 누적 Loss: {:.4f}, Acc: {:.4f}, AUC: {:.4f}".format(
i, np.mean(loss_history), acc.result().numpy(), auc.result().numpy()))
time = perf_counter() - start
print("Training Time : {:.3f}".format(time))
val_acc = BinaryAccuracy()
test_acc = BinaryAccuracy()
val_auc = AUC()
test_auc = AUC()
val_precision = Precision()
test_precision = Precision()
val_recall = Recall()
test_recall = Recall()
bce = tf.keras.losses.BinaryCrossentropy(from_logits=True)
val_loss = []
test_loss = []
print("Start Validation")
for x, y in val_ds:
y_pred = model(x)
val_loss.append(bce(y, y_pred).numpy())
val_acc.update_state(y, y_pred)
val_auc.update_state(y, y_pred)
val_precision.update_state(y, y_pred)
val_recall.update_state(y, y_pred)
acc_v, auc_v, precision_v, recall_v, ce_v = val_acc.result().numpy(), val_auc.result().numpy(), val_precision.result().numpy(), val_recall.result().numpy(), np.mean(val_loss)
print("val ACC: {:.4f}, AUC: {:.4f}".format(acc_v, auc_v))
print("val Precision: {:.4f}, Recall: {:.4f}, LogLoss: {:.4f}".format(precision_v, recall_v, ce_v))
for x, y in test_ds:
y_pred = model(x)
test_loss.append(bce(y, y_pred).numpy())
test_acc.update_state(y, y_pred)
test_auc.update_state(y, y_pred)
test_precision.update_state(y, y_pred)
test_recall.update_state(y, y_pred)
acc_r, auc_r, precision_r, recall_r, ce_r = test_acc.result().numpy(), test_auc.result().numpy(), test_precision.result().numpy(), test_recall.result().numpy(), np.mean(test_loss)
print("테스트 ACC: {:.4f}, AUC: {:.4f}".format(acc_r, auc_r))
print("테스트 Precision: {:.4f}, Recall: {:.4f}, LogLoss: {:.4f}".format(precision_r, recall_r, ce_r))
print("Batch Size: {}, Embedding Size: {}".format(data_batch_size, EMBEDDING_SIZE))
model.save_weights(
model_save_path +
'afm-phase2start({})-batch({})-k({})-AUC({:.4f})-CE({:.4f})-ACC({:.4f})-Precision({:.4f})-Recall({:.4f})-th({})-time({:.2f}).tf'.format(
phase_2_start, data_batch_size, EMBEDDING_SIZE, auc_r, ce_r, acc_r,precision_r, recall_r, np.round(threshold,2), time
))
%%time
run_afm(epochs=100)
