[논문리뷰] Human level control through deep reinforcement learning(2015)
1. 논문 선정 이유 및 개요
- 논문명 : Mnih, Volodymyr, et al. “Human-level control through deep reinforcement learning.” Nature 518.7540 (2015): 529-533.
- 이 연구는 Nature지에 기재되었으며, 인용횟수 9642회에 달한다.
- 딥 강화학습의 출발점인 DQN의 기본 논문이라 리뷰하고자 한다.
- 이 연구는 기존의 Q-network를 개선한 DQN으로 더 효율적인 강화학습을 진행한다. 이에 대한 결과로 Atari 게임에서 인간이 학습할 수 있는 수준(human-level)을 상회하는 성능을 보여, 다양한 환경에서 control policy들을 성공적으로 학습할 수 있음을 보여주었다.
2. Background
MDP
- 강화학습이란, 주어진 어떤 상황(situation)에서 보상(reward)을 최대화할 수 있는 행동(action)에 대해 학습하는 것이다. 이 일련의 상호작용을 Markov Decision Process(MDP)라고 한다.
- 이 MDP는 < 상태(S), 행동(A), 전이함수(T), 보상함수(R), discount factor(r)>으로 나타낸다. 탐험(Exploration)과 이용(Exploitation)
- 더 높은 보상을 받기 위해서는 주어진 상황에서의 더 적절한 행동을 선택(exploit)한다.
- 이때 각 action들의 가치에 대해 알기 위해서는 사전에 탐험(explore)을 할 필요가 있다 Exploration-exploitation dilemma
- 탐험을 위해서는 지금 당장 최선이라고 믿어지는 action을 포기할 수도 있어야한다. Policy
- 어떤 state에서 어떤 action을 취할 확률, π(a|s) Value function
- 상태 s에서의 Return의 기대값. 강화학습은 기대보상을 최대로 하는 정책을 고르는 것 (Expected Return = Value Function) Q function
- 정책 π 를 따를 때 어떤 state와 action에 대한 value function. 이 value function을 업데이트하는 것을 Q-Learning이라고 한다.
3. Challenges
- Q-Learning에서 Q함수(action-value function) 학습이 수렴(converge) 되지않고 분산(diverge)한다. 이 불안정성(instability)에는 다음과 같은 이유가 있다:
3.1 Correlation between samples
- 강화학습에서의 학습 sample은 시간에 따라 순차적으로 수집되기 때문에 correlation이 높다
- Sample간의 correlation이 높으면 학습이 불안정해진다. Sample들 간의 잘못된 상관관계가 생길 수 있다.
- 이 연구에서는 Experience Replay로 이 문제를 해결한다.
3.2 Non-stationary targets
- MSE(Mean Squared Error)를 이용하여 optimal action-value function을 근사할 때에 predict Q함수와target Q함수가 같은 파라미터 θ를 사용한다. 따라서 predict에 따라 θ 업데이트 시에, 같은 θ를 사용하고있는 target이 함께 값이 변하는 문제가 발생한다.
- 이 연구에서는 Q-target을 고정하고, predict Q함수를 따로 업데이트함으로써 이 문제를 해결한다.
4. Key concept
4.1. Convolution Neural Network
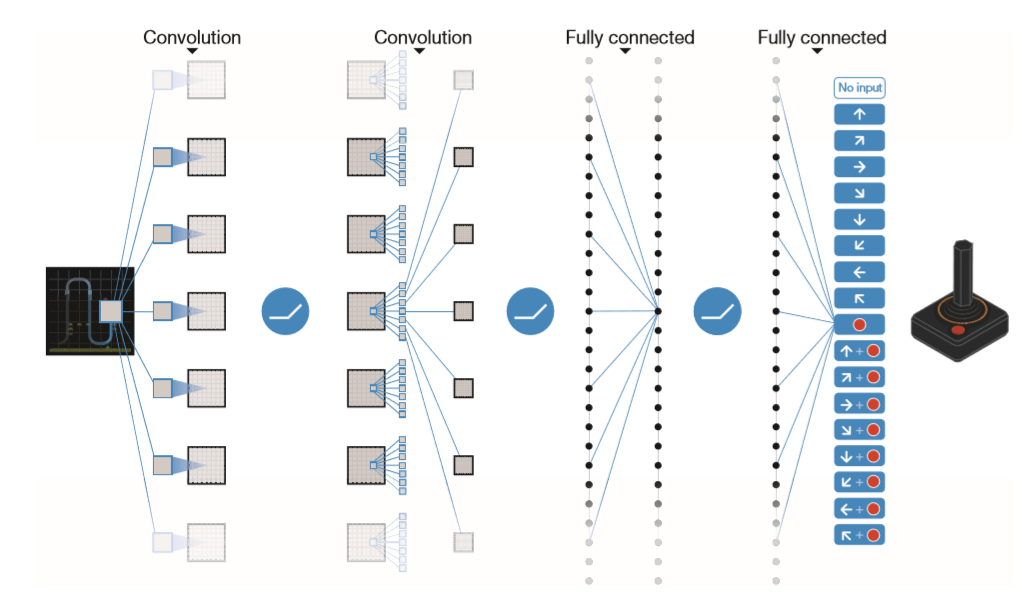
- 이 연구에서는, 한 가지의 네트워크를 사용하는 것이 아니라 더 많이 사용해서 더 여러가지 상황을 표현할 수 있게 한다. 이를 위해 이미지(pixel) 데이터를 입력 데이터로 사용한다. 즉, 환경에 따라 state의 도메인을 크게 바꾸지 않고 적용 가능하게 해준다.
- input은 게임화면 pixel값이며, output은 각 action에 대한 Q value를 나타낸다.
4.2 Exprience Replay : correlation 해결
- 경험 리플레이(Experience Replay) : transition(S, A, R, S’)을 memory(buffer)에 저장하고 batch 단위로 학습하도록 한다. 이를 통해 data (transition)간의 correlation을 없앨 수 있으며, batch 단위로 학습이 가능하다.
- 경험 리플레이는 루프를 돌면서 action에 대한 상태를 받아오고, 이를 버퍼에 일단 저장한다. 일정시간(step)이 지나면 이 버퍼에서 random하게 샘플을 가져와서 학습을 시킨다.
4.3 Fixed Q-targets : Non-stationary target 해결
- 일정 step마다 업데이트 되는 네트워크를 따로 추가하여, predict와 target network를 분리한다. 따라서 predict의 θ_bar를 따로 업데이트하다가, 어느정도 시간(step)이 지나면 일정 간격으로 predict 네트워크(weight)를 target 네트워크(weight)로 복사한다.
4.4 Gradient Clipping
- Loss function의 기울기의 절대값이 1 이상인 경우 1이 되도록 Clipping한다.
5. Method

- replay memory D : 학습하지 않고 일단 저장할 버퍼를 만든다
- action-value function : Q 네트워크를 만든다
- target action-value function : target Q 네트워크를 따로 만든다
- Execute action : 액션을 취하면서 (Execute action) 보상을 받아오게 된다(observe reward)
- Store transition in D : 학습시키지않고 일단 버퍼에 저장한다
- Sample random minibatch of transitions from D : 랜덤한 샘플을 가져온다
- Perform a gradient descent : 예측 네트워크를 업데이트 시킨다.
- Every C step : 어느정도 시간이 지나면 타겟 = 예측 으로 네트워크를 복사한다.
6. Result
- 실험 결과, Q-learning에서 발생하던 diverge문제가 해결되어 average action value가 점점 수렴하였고, 49개의 게임의 75%에 달하는 29개의 게임에서 인간 수준을 뛰어넘은 성능을 보여주었다.
7. 분석 및 개인 견해
- DQN은 보상함수인 Q함수를 극대화하는 문제에서, CNN을 사용하여 여러가지 상황을 표현할 수 있게 했으며, 경험 리플레이(Experience Replay)를 이용해 학습 sample 데이터의 상관관계 문제를 해결했다. 그리고 Q-target을 고정하기 위해 학습 네트워크와 target 네트워크를 분리하였다. 그 결과, 인간 수준을 상회하는 성능을 가진 Deep Q-Network를 통해 다양한 환경을 학습하는 것을 보여주었다.
Reference
- Mnih, Volodymyr, et al. “Human-level control through deep reinforcement learning.” Nature 518.7540 (2015): 529-533. (https://www.nature.com/articles/nature14236)
