[논문리뷰]BEM-DDPG : Towards optimal control of air handling units using deep reinforcement learning and recurrent neural network(2020)
Why this paper?
- 얻고자 하는 것 : 빌딩 에너지 소비 예측에서, DDPG 적용 논문 리뷰 + 시뮬레이션 데이터 말고 실제 데이터를 쓰는 법
- 빌딩 에너지 예측에서 action space는 연속적인 실수값이 많음.(온도 제어값, 밸브 제어 개도율 등) → “continous action spaces”
- DQN은 오직 이산적(discrete)이고 차원이 낮은 task에 유리→ action의 종류가 늘어날 수록 차원의 저주에 걸림
- 실제로 switch on/off 같은 제어값만 있는 주거용 스마트홈 에너지 예측은 DQN 아직 많이 쓰지만, 최근 빌딩 에너지 예측 연구들은 주로 DDPG 사용
- 시뮬레이션 데이터를 생성하는 과정에서 건물 구조를 지나치게 단순화함. DRL 훈련 환경을 위해 실제 작동을 근사화하기 위한 LSTM 네트워크 구현
- 구축된 LSTM 기반 DRL 훈련 환경에서 DDPG 알고리즘으로 최적 제어 구현
Proposed Process
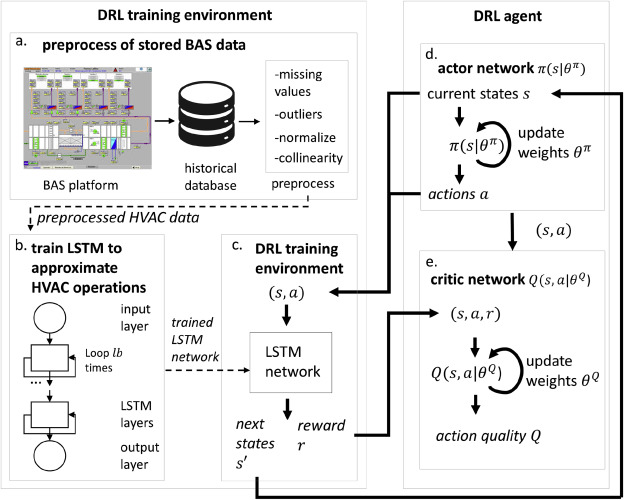
- 과거 운영 데이터 전처리 (1회성)
- LSTM 네트워크 구축 : 과거 운영 데이터를 사용하여 HVAC 작동을 근사화 (1회성)
- 시뮬레이터로 만들었을때의 단점(단기간 데이터만 됨, 지나치게 단순화함)을 해결하기 위함
- DRL 훈련 환경 : 훈련된 LSTM 네트워크를 함수로 래핑하여 훈련 환경 생성.
- DRL 에이전트 Actor 네트워크 : 현재 state를 입력으로 action을 선택.
- DRL 에이전트 critic 네트워크 : 현재 state, action, reward를 입력으로 누적 보상, action의 가치함수를 근사화, action의 quality를 반환함.
- DRL 에이전트는 받는 보상이 안정적인 값으로 수렴되어 최적의 정책을 생성할 때까지 훈련 기간 동안 action의 quality를 관찰하여 HVAC을 제어하는 방법을 학습함
- 과거 운영 데이터 전처리
- 2년 15분주기 33개 변수 데이터
- 결측값 처리 : 시계열 데이터이므로 이동 평균 방법 사용
- 이상치 처리 : z score 3으로, 평균값의 3 표준편차를 초과하는 매개변수 값 제거.
- 정규화 : min-max scaling
- 공선 매개변수 제거 : 피어슨 상관계수(+-0.9) 사용하여 공선성 계산.
- LSTM 네트워크 구축
- 전처리한 실제 과거 운영데이터를 토대로 HVAC 작업을 근사화하는 LSTM 네트워크 훈련
- 네트워크의 weight와 bias는 LSTM 출력(ex. 과거 판독값을 고려한 예측 팬 속도)과 실제 훈련 샘플(ex. 실제 팬 속도) 간의 차이를 최소화 하여 학습. SGD로 최적화
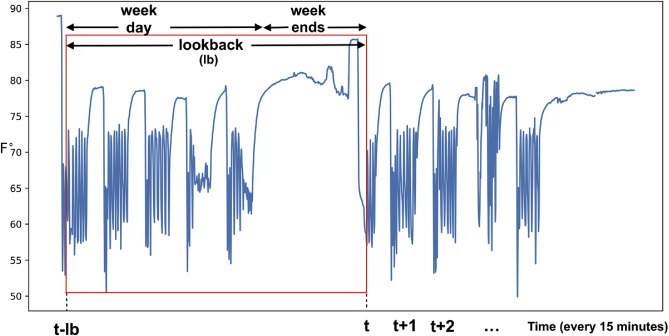
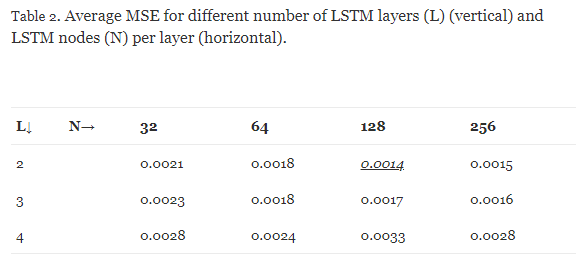
- 가장 성능이 좋은 LSTM 아키텍처가 네트워크를 훈련하는데 사용됨
- DRL 훈련 환경
-
전체 Reward Design
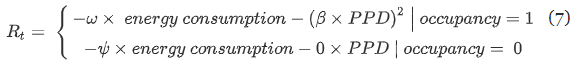
- 점유 기간(1) / 비 점유 기간(0) 분리 : 비 점유 기간에는 열 쾌적성 유지 제약이 없으므로 음의 에너지 소비가 유일한 보상
-
- DRL 에이전트
(참고)DDPG
- idea
- Actor-Critic Method : Continous action space를 가진 문제에서 DDPG가 더 좋다. Q function을 구한 후 최적의 policy를 찾는것보다(DQN) Policy Gradient를 통해 policy를 바로 학습할 수 있어서 더 좋다
- Deterministic (Not Stochastic) : Policy gradient를 수행할 때 action에 대한 적분을 수행하지 않아 계산 효율성이 증가한다.
-
model-free, off-policy, actor-critic
Model Free
-
Action Value Function
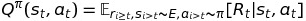
-
Action Value Function (벨만 form)
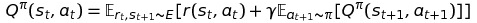
-
Model-free = policy iteration = policy evaluation + policy improvement
- policy evaluation : action-value function을 TD Learning으로 estimate
- policy improvement : action-value function을 maximize하는 greedy 방법. policy graident
Off-Policy Actor-Critic(Off-PAC)
- Critic : 경로에 대한 off-policy로 state-value function에 대해 estimate
- Actor : off-policy로 stochastic gradient를 ascent. 파라미터 θ를 조정함
SPG(Stochastic Policy Gradient)
- Critic : action-value function을 estimate.
- Actor : stochastic gradient ascent로 정책 π의 가중치 θ를 조정함
- Policy π를 확률분포로 나타낸다. 이 확률 분포는 파라미터 θ에 대해서 stochastic하게 action을 선택함.
- Policy Gradient는 이런 stochastic policy를 샘플링하고, reward를 더 좋게 하는 방향으로 policy parameter를 조절하는 것.
DPG
- SPG는 action space가 다차원인경우 state와 action spaces를 다 적분해야하는데, DPG는 state space에 대해서만 적분해주면 됨.
- DPG(Deterministic policy gradient)는 SPG에서 policy variance가 0이 되는 limit case라고 볼 수 있음
- 즉, Deterministic Policy(mu) 학습, Off-Policy Actor-Critic, Stochastic 정책 π로 행동을 선택.
- Critic : true action-value function Qmu 대신에, 미분가능한 action-value function Qw로 대체. 행동 정책 β에 의해 생성된 경로를 따르는 off-policy로서 action-value function Qw를 estimate함 (Q-learning)
- Actor : Off-policy Deterministic Policy Gradient로 파라미터 θ를 조정함
-
