[논문리뷰]Whole building energy model for HVAC optimal control: A practical framework based on deep reinforcement learning(2019)
Why this paper?
- Energy and Buildings, 2019 / Reference count - 69
- 건물 에너지 공급 제어에 대해, “실용성”을 중시한 사례 중심의 “프레임워크” 제시
- 제어 방법을 기존의 열역학적 룰 기반이 아닌 강화학습 기반의 방법 사용 → 강화학습 방법을 건물 에너지 수요 절감에 적용할 때 어떻게 수식을 쓰는지? 어떻게 적용하는지 보기 위함
- 시뮬레이터의 데이터를 어떻게 가져다 쓰는지? 실제 빌딩에 적용하기 위해 어떻게 검증하는지? 보기 위함
Abstract
- 전체건물에너지모델(이하 BEM)은 건물 에너지 시뮬레이션에서 물리학 기반 모델링을 사용 → 최근 HVAC(난방,환기,공조기) 시스템 제어 목적으로 이 모델 사용하고 싶으나, 실제 적용이 약간 어려움
- 이 연구는 “건물 에너지 모델링 → 베이지안 방법/유전 알고리즘을 사용한 다중 목적 BEM 보정 (Multi-objective Model Calibration)→ Deep Reinforcement Learning 훈련 → 시뮬레이션 결과 평가 → 배포” 순의 프레임워크 제시
- 연구의 목적은 강화학습 알고리즘을 이용하여, 모델을 이용하지 않고도(model-free), 건물 전체 설비 시스템에 대해(whole building), 자가 학습으로 최적 제어를 위한 정책을 발전시켜(self-learning), 에너지 절감과 실내 환경 쾌적 상태 유지를 동시에 만족시킬 수 있음을 보이기 위함이다(multi-objective optimization)
1. Introduction
- HVAC 시스템의 제어는 에너지 소비에 큰 영향. 따라서 “최적 제어” 전략에 대한 연구가 많았음
- BEM은 최적 제어 방법에 쓰이는 모델이 종종 되곤 함. 원래 BEM은 건물 설계에 자주 사용됨.
- 이 연구는 HVAC 최적 제어에 BEM을 사용하기 위한 실용적인 프레임워크를 제안, 평가하는 것이 목적
1.1 BEM-based predictive control (Model Predictive Control)
- MPC(Model Predictive Control)는 모델의 예측 기간 동안에 제약 조건을 만족함과 동시에 비용함수를 최소(혹은 최적)로 하는 제어 변수의 값을 결정.
- 비용함수란, 제어를 통해 최종적으로 달성하고자 하는 목표. 에너지 소비, 에너지 요구량.
- MPC 방법에서, 열역학 법칙등을 이용한 white box 모델을 사용할 경우, 수식 기반으로 풀기 때문에 모델이 정교해질 수록 연산에 소요되는 시간이 기하급수적으로 증가한다. → 프레임워크에 쓰려면 단순화해야함
- EPMPC(EnergyPlus MPC) : 시뮬레이션 프로그램 EnergyPlus를 활용한 실시간 제어를 제시. 그러나 예측 시간 범위가 작아서, 확장성이 제한적임
- 비실시간 BEM기반 제어방법 : 휴리스틱 최적화를 사용해 다음 날에 대한 최적 설정값 일정을 미리 계산
- 위의 방법들은 시뮬레이터에서만 테스트되었기 때문에, 실제 가능성 및 성능을 알 수 없다.
1.2 Reinforcement learning control
- 강화학습(이하 RL)은 Model-Free 제어방법. RL은 실제 건물 운영 중에 시행착오를 통해 최적의 제어 전략을 학습(온라인학습)
- 안정성을 이유로 HVAC 시뮬레이터를 이용하여 RL 에이전트를 오프라인으로 훈련하고자함
1.3 Objectives
- 이 연구는 제어를 위해, BEM을 사용하기 위해 DRL을 기반으로 하는 실용적인 프레임워크 개발 → 사례연구를 통해 방법론 시연, 성능을 평가
2. Control framework
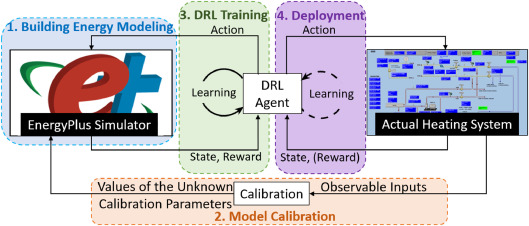
step1. 빌딩 에너지 모델링 : EnergyPlus 시뮬레이터를 이용하여 빌딩 에너지 모델(BEM) 생성. 이 모델은 오프라인 DRL 훈련을 위한 시뮬레이터로 사용됨
step2. 모델 보정(Model Calibration) : 구축된 BEM은 시뮬레이션과 관찰 사이의 간격을 최소화하기 위해 관찰된 데이터를 사용하여 보정됨
step3. DRL 훈련 : 보정된 BEM은 최적 제어 전략을 개발하기 위해 RL 에이전트를 오프라인으로 훈련시키는데 사용됨
step4 배포 : 훈련된 RL 에이전트가 실제 시스템에 배포되어, 대상 HVAC시스템에 대한 제어 신호를 실시간으로 생성한다.
2.1 BEM-DRL step1 : building energy modeling
- BEM은 열역학 기반으로 설계됨. 이 모델은 모든 제어시간 t에서 에너지 절감과 열쾌적성을 만족하는 메트릭을 예측하기위해 제어(action)하는 “시뮬레이터”로 사용.
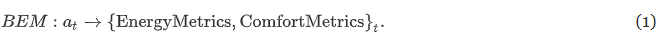
2.2 BEM-DRL step2 : model calibration
- 시뮬레이터로 사용할 BEM이 잘 만들어졌는지 검증하고 보정한다!
2.2.1 Automated calibration
- 자동 보정 : 관찰 및 시뮬레이션된 건물 성능 데이터를 비교하고 관찰과 시뮬레이션 간의 불일치를 최소화하기 위해 다양한 유형의 수학적 및 통계적 접근 방식을 사용
- BEM은 EnergyMetrics와 ComfortMetrics 모두에 대해 보정 필요
Bayesian calibration
- 가우시안 보정 방법 : 확률 분포를 추정하여 모델을 보정
- Chong and Menberg가 제안한 “Guidelines for the bayesian calibration of building energy models”(2018) 베이지안 보정 기법을 “응용하여” 사용
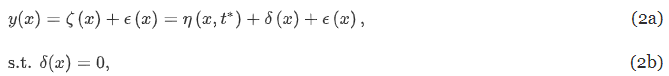
- y, ζ, η : 보정 목표 변수. 각각 관측/실제/시뮬레이션된 건물 성능 behavior (즉, HVAC 에너지 소비와 같은 교정 목표)
- x : 관측 가능한 입력 매개변수. 관측할 수 있지만 조작할 수는 없는 매개변수 (기상조건 등)
- t : 미지의 참값. 침투율과 같이 조작 가능한 매개변수.
- δ : 모델 부적절함을 수정하기 위한 불일치항(discrepancy term) → BEM이 대상 HVAC 시스템을 적절하게 모델링한다고 가정하기때문에 강제로 0이 됨
- ϵ : 관측 오차

- ϵ의 분포가 가우스 분포라고 가정하면 베이즈 정리에 따라 y 가 주어졌을 때 t 의 사후 분포를 위와 같이 쓸 수 있음. P는 확률 분포, L은 우도 함수.
- 다운샘플링 : 베이지안 보정의 계산시간은 보정 데이터 y(x), η(x,t)의 데이터 크기에 따라 기하급수적으로 증가. 따라서 원본 보정 데이터 세트를 더 작은 데이터로 다운 샘플링
- 새로운 방법 convex combination method 제시 : 이전에 제안된 방법은 “단일 목표 보정”을 위해 설계 되었기 때문에 지금 여러 건물 성능 매트릭을 보정해야하는 본 연구와 안맞음 → 여러 건물 성능 메트릭을 보정하기 위해 convex combination 가중치(mu)을 사용한 method 제시
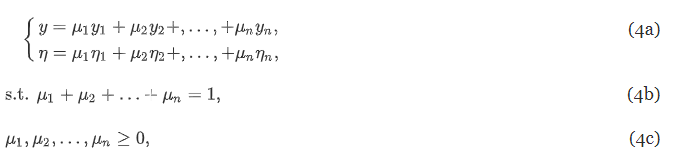
Genetic algorithm
- GA : 다중목표 최적화(Multi-objective optimization)에 사용되는 휴리스틱 검색 방법
- 관측된 건물 성능 메트릭과 시뮬레이션된 건물 성능 메트릭 간의 불일치를 최소화하는 calibration parameter를 찾고자 함.
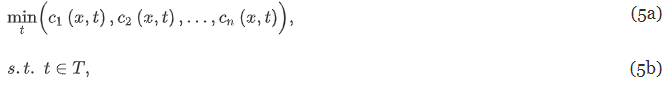
- c : 관측된 건물 성능 메트릭과 시뮬레이션된 건물 성능 메트릭 간의 오류함수
- x : 관측 가능한 입력 매개변수(예: 기상조건)
- t : 보정 매개변수 (T : t의 실행 가능한 선택을 나타내는 이산 집합)
2.2.2 Model evaluation
- 성능 평가 : normalized mean bias error(NMBE), cumulative variation of the root mean square error (CVRMSE)
-
NMBE : 정규화된 표본 공간의 오류 평균. 시뮬레이션된 데이터의 전반적인 동작을 나타내는 좋은 지표가 됨.
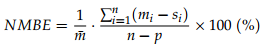
-
CVRMSE : 측정값과 시뮬레이션 값 사이의 오차를 통해 변동성을 측정함. 시뮬레이션된 데이터가 얼마나 실 데이터의 모양을 잘 반영하는지 좋은 지표가 됨
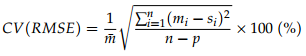
- 기준 : ASHRAE Guideline 14에서 제시하는 기준은 시간당 NMBE 및 CVRMSE가 각각 10% 및 30% 미만
2.3 BEM-DRL step3. DRL training
2.3.1 Technical background of deep reinforcement learning
- 보정된 BEM은 HVAC 시스템에 대한 최적 제어 정책을 학습하기 위해 오프라인에서 강화학습 에이전트를 훈련하는 시뮬레이터로 사용됨
Standard reinforcement learning problem
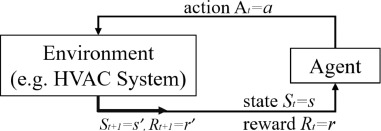
- 동작 : 제어 타임 스텝 t 에서 에이전트가 상태 s_t와 보상 R_t를 관찰하여 제어 A_t를 제공.
- 에이전트 제어 정책 π: S t → A t
- 에이전트 목표 : 각 제어 타임 스텝에서 누적 보상을 최대화하는 제어 정책을 찾는 것 . t 시점에서 결정한 행동에 따른 보상 R_t+1 뿐만 아니라 누적 보상 전체를 최대화하는 것이 목표.

- 정책, 상태-가치 함수 아키텍쳐

- 상태-가치 함수(V)와 행동-가치함수(Q)
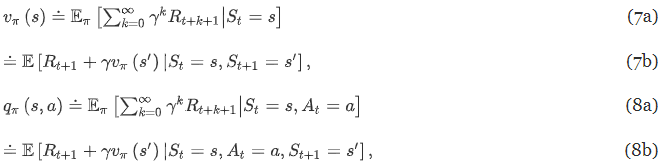
- γ : 보상 할인 계수. 미래를 포함해 보상들을 반영, 보상의 총합이 발산하지 않도록 함
- 상태-가치 함수 V : 주어진 정책을 따랐을 때 주어진 상태에서 기대되는 반환값
- 행동-가치 함수 Q : 주어진 상태에서 하는 행동에 의해 기대되는 반환값

- 가중치 벡터 근사화 : 가중치 통해 선형 함수, NN 등에서 사용 가능
Advantage actor critic(A2C)
-
표준 강화학습 문제는 최적화 문제로 바꿀 수 있다. 정책 πθ(s, a)에서 각 시점의 평균 보상을 최대화하는 θ를 찾는 문제로.

- d(s) : 정책 πθ에 따라 s0에서 시작하는 마르코프 체인의 상태 s에 대한 정상확률분포(stationary distribution)
- R : 액션 a를 취하는 상태 s에서의 보상
-
Gradient Descent 로 최적화 문제를 푼다
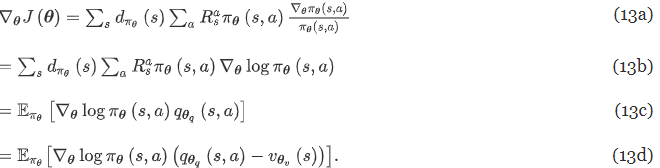
- 13c는 Policy Gradient방법에서 착안 : 미분을 통해 policy 값을 업데이트하며 최적의 policy 를 찾아간다 → 그런데 에이전트 행동 확률을 직접적으로 학습하는건 불안정하니까 가치 함수를 같이 써서 안정성을 높이자
- Actor : Policy Network(행동-가치 함수) & Critic : Value Network (상태-가치 함수)
- 13d에서 뒤의 항은 zero 항으로 학습 안정성을 높이고 variance를 줄이기 위해 삽입
-
Gradient 업데이트
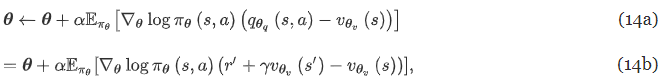
- α : learning rate, r’ : 실제 관측된 보상
- 14b는 (8b)의 식에 따라 도출
- 그런데 θ_v는 우리가 잘 모름. 어떻게 구하냐면 → 상태-가치 함수로 구할 수 있음
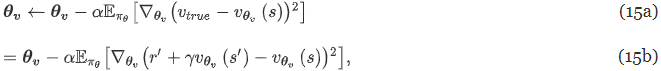
- 15b는 (7b)의 식에 따라 도출
- 따라서 최종 학습 업데이트는 다음과 같이 된다
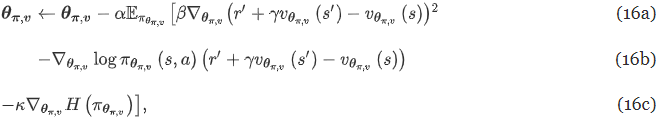
Asynchronous advantage actor critic(A3C)
- 본 연구에서는 A2C의 학습속도 향상 시키기위해 A3C 사용함.
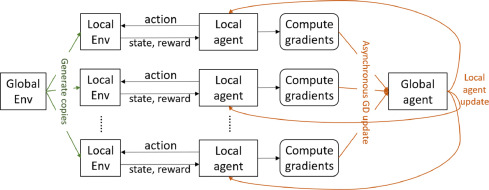
- A3C는 여러 RL 에이전트를 동시 실행한다. 각 RL 에이전트는 동일한 시뮬레이터의 복사본 사용하여 에이전트에 대한 GD 업데이트를 비동기적으로 수행.
- 기존 e-greedy 방법과 비교해 비동기식 방법은 탐색 효율성을 향상, 강화학습의 “exploitation-exploration” 딜레마를 해결할 수 있음
Key terminologies
- 제어 타임 스텝(Control time step) : RL 에이전트가 상태 및 보상을 관찰하고 제어 작업을 실행하고 결과 상태 및 다음 시간 단계의 보상을 기다리는 시간 간격
- 시뮬레이션 타임 스텝(Simulation time step) : 시뮬레이션에 정의된 타임 스텝. 제어 타임 스텝과 독립적. 제어 타임 스텝이 15분이고 시뮬레이션 타임 스텝이 5분이면, RL 에이전트가 각 3 시뮬레이션 타임 스텝마다 시뮬레이터와 상호 작용함을 의미.
- 시뮬레이터 에피소드(Simulator episode) : 시뮬레이터의 시뮬레이션 기간. RL 훈련 동안 시뮬레이션은 여러 에피소드에 대해 반복
- 상호 작용 시간(Interaction times) : RL 에이전트(A3C의 모든 로컬 RL 에이전트 포함)가 환경과 상호 작용하는 횟수(하나의 상호 작용은 RL 에이전트가 하나의 제어 타임 스텝을 완료함을 의미)
2.3.2 State, action and reward
-
상태 : 환경에 대한 RL 에이전트의 observation. 빌딩 구조는 열 역학 반응이 느릴 수 있으므로, 상태는 현재와 과거(historical) 관측의 스택이어야 함

- ob : 제어 타임 스텝에서 에이전트의 관측치
- t : 현재 제어 타임 스텝
- n : history window
-
행동 : 제어 행동 선택의 개별 집합

-
보상 : 상태/동작이 얼마나 좋은지 나타내는 [0,1] 범위의 스칼라 값. 사용자 정의. 보상은 에너지 소비가 높거나 열쾌적성이 낮을때 작고, 에너지 소비가 낮고 열쾌적성이 허용가능수준이면 커야함.
2.3.3 EnergyPlus simulator for reinforcement learning(EPRL)
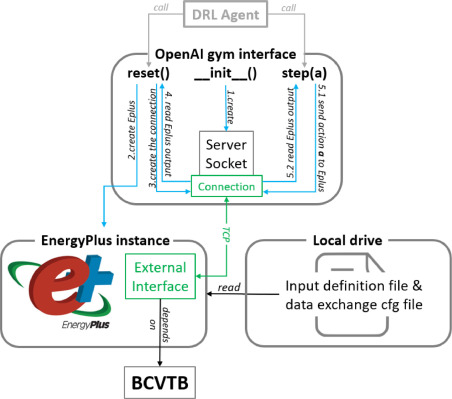
- 본 연구에서 Python 기반의 OpenAI Gym 인터페이스에서 EnergyPlus 모델을 래핑하는 EPRL(EnergyPlus Simulator for Reinforcement Learning)을 개발함
- ERPL 역할 : 강화학습환경(시뮬레이터)을 생성하여 RL에이전트가 EnergyPlus 모델과 상호작용하여 최적의 제어 정책을 학습할 수 있도록 함.
2.4 BEM-DRL step 4 : deployment
- 정적(Static) 배포 : RL 에이전트가 학습 없이 static 함수로 배포. 컴퓨팅 파워가 덜 듦. 그러나 BEM이 보정이 필요할 수도 있고, HVAC 시스템의 키 특성이 바뀌면 RL 에이전트를 다시 훈련시켜야할 수도 있음
- 동적(Dynamic) 배포 : RL 에이전트가 지속적인 학습(continous learning)을 함. 각 타임 스텝에서 에이전트는 상태와 보상을 계산 후 트레이닝 단계에서 자체 업데이트 함. 그러나 동적 배포는 제어 정책을 불안정하게 만들 수 있음
2.5 Normalized energy saving performance evaluation
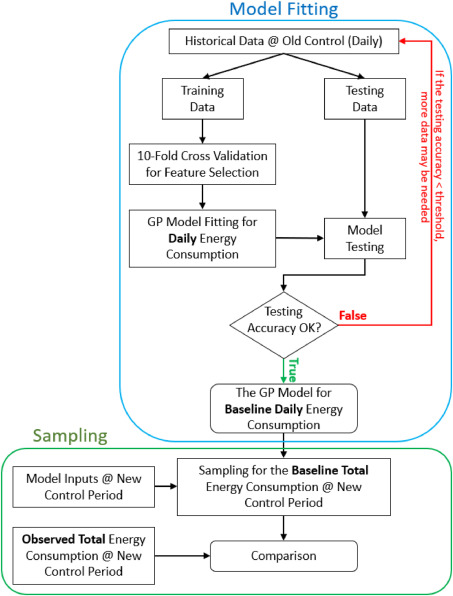
- 에너지 소비는 제어 전략, 실외 온도, 일사량 등 여러 요인에 영향 받음.
- 이 연구에서 새로운 제어 전략의 정규화된 에너지 절약 평가를 수행하기 위한 “확률적 데이터 기반 접근 방식”을 제안함 : 이전 방법에 다중 에너지 영향 요인, 비선형 입출력 관계 및 확률을 포함하도록 확장했음
Model Fitting
- old 제어 기간의 historical 데이터를 가우시안 프로세스(이하 GP) 모델에 피팅함
-
가우시안 프로세스(GP) 모델 = baseline daily HVAC 에너지 소비 모델

- 테스트 정확도(GP 모델 예측의 평균 기반)가 미리 정의된 임계값을 통과하면 샘플링 부분에 GP 모델을 사용할 수 있음
Sampling
-
피팅된 GP 모델을 사용하여 new 제어 기간에서 baseline total 에너지 소비의 샘플링 분포를 생성
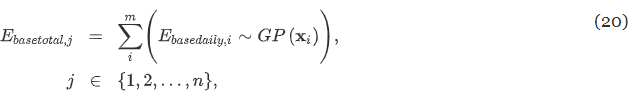
- E_basedaily : GP 모델에서 샘플링한 new 제어 기간의 baseline daily HVAC 에너지 소비
- i : new 제어주기 m일 중 1일 , j : 전체 baseline 샘플 n개중 1개
-
위 식을 사용하여 n번 샘플링 한 후 new 제어 기간에서 baseline total HVAC 에너지 소비의 표본 분포를 나타내는 n개의 값 세트를 얻음. → 분포함수를 근사화 할 수 있음. 통계적으로 solid한, 에너지 절감 결론을 내기 위해, new 제어 기간에서 관측된 total HVAC 에너지 소비와 비교할 수 있게됨!
3. Implementation of the case study
3.1 Building and system
- 사례연구건물 : 미국 오피스 빌딩 “난방 시스템”
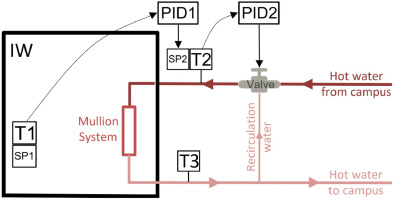
3.1.1 Baseline control logic
- 아래 난방 시스템은 실내 난방 수요에 대해 공급 온수 온도를 조정함.
- PID1 컨트롤러 : 평균 실내온도(T1)과 설정값(SP : SetPoint) 사이의 오차를 기반으로 급수온도설정값(SP2)를 계산함.
- PID2 컨트롤러 : 급수온도(T2)와 설정값(SP2) 간의 오차를 기반으로 밸브 개방상태를 조절함
3.1.2 Energy metric
-
“시스템 난방 수요” 가 에너지 메트릭이 됨.

- Cp : 일정한 압력에서 1도 올리기위해 필요한 열용량
- m : 시스템 공급수의 질량 유량
3.2 Optimal control objective
- 제어 목표 : 시스템 난방 수요를 줄이고, 허용 가능한 열 쾌적성을 유지하기 위한 최적 제어 정책을 개발하는 것
- 열 쾌적성 메트릭 : PPD(predicted percentage of dissatisfied)
3.3 Building energy modeling of IW
3.3.1 Model structure
Model Input & Output 정의
- Output : 급수온도 T2,T3에 따른난방 수요(에너지 메트릭), T1 실내 온도 IAT (열쾌적성 메트릭), 평균 PPD(열쾌적성 메트릭)
- Input : SP1 평균 실내 온도 설정점, SP2 급수온도 설정점
-
SP1 BEM (실내 온도 설정)
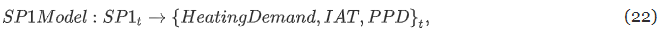
-
SP2 BEM (급수 온도 설정)
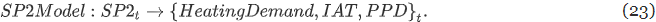
시뮬레이터 동작에 맞게 Model 수정
-
PID 컨트롤러 PID1은 급수 온도 설정값을 결정하고, PID2는 밸브 개방 상태를 결정한다. Energyplus에서는 출구 온도 설정값만 정의할 수 있다. 따라서 다음 수정 모델을 제안한다.

- PIDModel : PID컨트롤러 모방하는 EnergyPlus 외부의 data-driven 모델.
- PIDx : 관측 가능한 입력, T2 : 급수 온도 사이의 관계를 모델링함
- EplusModel : 관측된 급수 온도 T2를 사용해 에너지 성능 메트릭과 열쾌적성 성능 메트릭을 예측.
- SP2Model은 밸브를 모델링할 수 없기 때문에 입력이 설정값 SP2이 아니라 급수온도 T2가 됨
- 충분한 안정화 시간이 주어지면 T2가 SP2에 가까워지므로, 긴 제어 타임 스텝을 사용하면 됨
- PIDModel : PID컨트롤러 모방하는 EnergyPlus 외부의 data-driven 모델.
3.3.2 EnergyPlus modeling(EplusModel)
- EnergyPlus에서 IW와 비슷한 환경으로 시뮬레이션 환경 조성
- 시뮬레이션 환경 조성에 사용한 모델링 매개변수는 시뮬레이션된 열 동작이 관측 상황과 일치하는지 확인하는 calibration 영역 에서 찾을 수 있음.
3.3.3 PID controller modeling (PIDModel)
- PID 컨트롤러는 if-then-else 규칙이 포함되어 있기 때문에 RandomForest를 사용해 PIDModel 생성
-
PIDModel Input
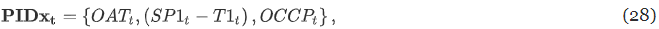
- PIDx : 관측 가능한 입력
- OAT : 외기 온도, SP1 : 실내 온도 설정값, T1 : 실내 온도, OCCP : 예정 점유 플래그(재실여부)
3.4 Model calibration of IW BEM:SP2Model
- SP2 BEM (급수 온도 설정)
3.4.1 Calibration Objective
- 난방수요와 실내 온도의 시뮬레이션 데이터와 관측본 사이의 간격을 최소화하기 위함
3.4.2 Selection of the calibration parameters
- EnergyPlus에서 시뮬레이션 환경으로 만든 것들의 파라미터 : 단열재 두께, 열전도율, 복사 표면 총 면적 등..
3.4.3 Calibration datasets
- 난방시즌(1월~3월)의 관측데이터 사용
- 데이터 세트
- SP2Model의 Input : 외기온도, 실외습도, 직사광선, 풍속, 급수온도(T2), 공급수질량유량
- Calibration Objective : 실내공기온도, 난방수요
3.4.4 Implementation of Bayesian calibration
-
x에는 위에서의 input이 들어감, t에는 calibration parameter가 들어감
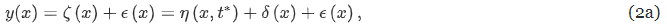
-
calibration objective인 실내공기온도, 난방수요는 관측치는 y1과 y2가 되고, 시뮬레이션값은 η1, η2로 들어감

3.4.5 Implementation of genetic algorithm
- 2가지 오류함수 c1, c2가 정의됨
-
c1은 실내공기온도에 대한 5분 CVRMSE가 들어감, c2는 난방 수요에 대한 시간당 NMBE가 들어감

3.4.5 Bayesian calibration results
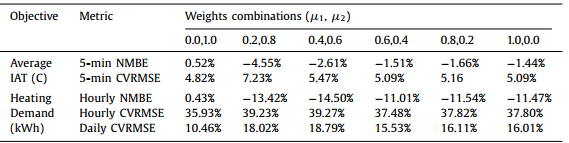
- 두개의 교정 목표는 가중치 μ1(실내공기온도용), μ2(난방 수요용)으로 convex combined 된다.
-
가중치 조합에 따른 모델링 오류
-
해석 : “μ1=0, μ2=1” 즉, 난방수요 데이터에 대해서만 보정할 때 더 나은 결과를 제공. 난방 수요와 실내공기온도 사이에 강한 상관관계가 있기 때문이라고 생각됨! 그리고 CV도 난방수요가 훨씬 큼
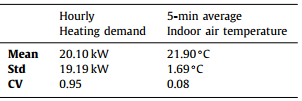
3.4.6 Genetic algorithm results
3.5 Model calibration of IW BEM:SP1Model
- SP1 BEM (실내 온도 설정)
3.5.1 Calibration objective
3.5.2 Calibration dataset for PIDModel
3.5.3 PIDModel results
3.5.4 SP1Model results
3.6 Model calibration of IW BEM:Model selection
- SP1 Model(실내 온도 설정)과 SP2 Model(급수 온도 설정)이라는 두개의 BEM은 이전 섹션에서 보정되었음
- 이 중 SP2 Model이 실내 공기 온도와 난방수요라는 두 가지 성능 메트릭의 정확도에 대해 더 나은 균형을 달성함. 따라서 DRL 훈련은 SP2Model 사용
- 제어점 : SP2 급수 온도 셋포인트
3.7 DRL Training based on the IW BEM(SP2model)
- 최적 제어 목표 : 난방 수요 소비를 줄이고 허용가능한 열 쾌적성 수준을 유지하는 것. 열 쾌적성 메트릭은 PPD를 사용
3.7.1 State Design
- 상태 Ob : 요일, 시간대, 외기온도, 실외습도, 풍속, 풍향, 태양복사열, 직사광선, 열교환기셋포인트(∘ C), 평균 PPD, 급수 온도 설정값(∘ C), 실내온도IAT, 실내온도IAT셋포인트, 점유 플래그(재실여부플래그 ex.평일 오전8시~오후7시)
- 상태 정규화 : 0~1
3.7.2 Action Design
- 액션 : 급수 온도 셋포인트(∘ C) ex. turn-off, 20∘ C, … , 60 ∘ C
3.7.3 Reward Design
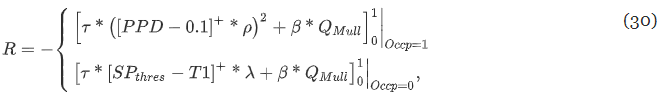
- PPD : 열쾌적성
- Q : 마지막 제어 타임스텝 이후의 난방 수요
- T1 : 실내공기온도
- Occp : 점유 모드 플래그 (1재실 / 0부재)
- τ, β, ρ, λ, SP : 하이퍼파라미터
3.7.4 Training setup
- 훈련대상 날짜 1월~3월 (난방기간)
3.7.5 Simulation performance results
- 원래 DRL 성과는 에피소드의 누적 보상으로 평가됨. → 그러나 에너지 수요에서 보상은 난방 수요와 열쾌적성 성능의 조합. 누적 보상 값은 의미가 없음.
-
평가는 난방수요절감, PPD 개선, 누적보상 세 개를 살펴봐야함.
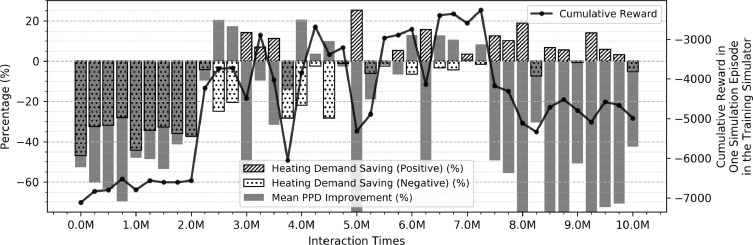
- 위 그래프는 기존 제어 방식과 비교했을 때 난방수요와 PPD가 얼마나 증가/감소했는지 보여줌
- 보상은 증가하다가 감소함. RL 에이전트가 725만 상호 작용 시간 이후 로컬 차선책 영역에 멈춤
- PPD가 대폭 개선되고, 난방수요가 작게 증가하면 높은 평가 보상을 가져왔음. 보상 함수 설계가 현재 열쾌적성 향상에 더 유리함을 나타냄.
- 열쾌적성을 과도하게 저하시키지 않으면서 난방수요를 감소시키는 결과를 선택하려면, 주관적 결정 필요. 이 연구에서는 상호 작용 시간 3.25M에 훈련된 RL 에이전트를 사용.
- 선택된 RL 에이전트를 실제 날씨 데이터를 활용해서 EnergyPlus 모델에서 테스트 (테스트 시뮬레이터 동작) → 기준 제어 로직에 비해서 난방수요 절약, 열쾌적성에 대한 불만율인 PPD는 증가
3.8 Deployment of the DRL control
- 훈련된 RL 에이전트를 static하게 배포함
3.8.1 Normalized energy saving performance evaluation results
- 섹션 2.5에 기술된 정규화된 에너지 절약 성능 평가 방법을 따라, 기존의 규칙 기반 제어와 비교해서 RL 에이전트의 절약 성능을 정량화.
- GP 모델에서 생성된 일일 난방 수요 샘플링
- 총 난방 수요 샘플링을 마치면 다음과 같은 분포로 나타나는데, 에너지 비교를 통계적으로 확실히 하기 위해 약 5번째 백분위수에서 기준 난방 수요를 선택함. 기준 난방 수요가 95% 이상의 확률로 이 값보다 높다는 것을 나타냄. 이 기준 난방 수요값(28940kWh)을 DRL 제어시의 난방수요와 비교한다!
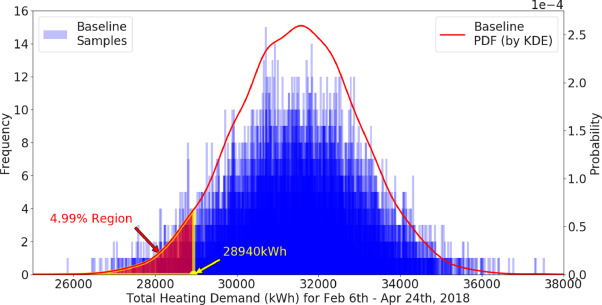
- DRL 제어 후 관찰된 총 난방 수요와 기존 제어 로직에서의 난방 수요 비교

4. Discussion
- BEM은 물리학 기반 모델. 그래서 데이터 기반 모델보다 많이 쓰임.
- BEM 기반 제어를 하려고 해도 실무적으로 어려웠지만, 이 연구는 실제 난방 시스템에서 BEM + 강화학습 기반 프레임워크를 제안
- 그러나 BEM은 실제 건물 운영데이터에 적용하려면 calibration이 반드시 필요하다. (향후 연구 필요한 부분 or model free로 가야하는 부분)
- RL 에이전트를 수동으로 선택함
5. Conclusion and future work
- 제어 프레임워크 : 건물 에너지 모델링 → 모델 보정 → DRL 훈련 → 제어 배포
- 78일 배포 테스트 결과, 기존 rule-based 제어 로직에 비해 95% 이상의 확률로 16.7%의 난방 수요를 절약
- 향후에는..
- BEM 보정이 까다로우므로, 지나치게 정확한 BEM을 개발할 필요가 없다. 오히려 RL 에이전트가 과적합됨. 보정된 BEM이 달성해야하는 정확도 수준에 대한 실용적 지침을 설정해보자
- 강화학습의 적응성. 장비 노후화에 따른 효율성 저하, 운영 일정 변경 등의 동적 특성에 어떻게 적응할 수 있는지 연구 필요
What’s Next
Insight
- 빌딩 제어 부분은 시뮬레이션 설계 부분에서 model calibration이 필요
- 위 논문처럼 프레임워크를 개발, 본인 연구에 맞게 수식 수정하는 것도 논문 방향 될 수도..
- 그리고 위 논문은 설비 1개 대상이 아닌 whole building 제어라서.. 범위를 좁혀서 설비 모듈당 제어하는 연구도 살펴볼 필요 있음.
연구 진행 상황
- 오피스빌딩 BEMS 데이터 수집 완료
- EnergyPlus 설치 완료 → 오피스빌딩 시뮬레이션 데이터셋 연동 필요
논문 리뷰 방향
- 강화학습 적용 알고리즘 부분을 어떻게 적용했는지 알고리즘 중점적으로 리뷰
- Practical implementation and evaluation of deep reinforcement learning control for a radiant heating system (2018)
- 어떤 경우에 강화학습 방법 중 어느 방법이 성능이 좋은지, 각 알고리즘에 대한 이해 기반으로
- Study on deep reinforcement learning techniques for building energy consumption forecasting (2020)
