[논문리뷰]Factorization Machines(2010)
Why This Paper?
- 추천시스템에서 user item 뿐만 아니라 다른 메타 데이터(time 등)를 활용
- 이 개념을 가지고 DeepFM 등으로 발전
- 향후 연구 방향이 context aware 추천시스템에서의 feature selection.(목적 : context aware recommender에서의 efficiency + 추천설명력) 이 논문은 user와 item 뿐만 아니라 다른 feature 다루는 베이스 논문이라 보려고 함.
Abstract
- Factorization Machine은 SVM과 Factorization Model의 장점을 합친 모델
- SVM : Support Vector를 찾아서 이 기준으로 분류/회귀
- Factorization Model : Matrix Factorization(행렬분해를 통한 잠재요인 분해), tensor factorization
- Real valued(실수) Feature Vector를 활용한 General Predictor이다.
- 분류/회귀 전부 가능
- Factorization Machine의 식은 linear time이다. = 계산 복잡도가 낮다. (linear complexity)
- 일반적인 추천 시스템은 special input data와 그 데이터에 맞는 최적화가 필요한데, Factorization Machine은 어느 곳에서든 쉽게 적용 가능하다.
Introduction
- Factorization Machine은 general predictor이며, high sparsity에서도 reliable parameters를 예측할 수 있다.
- Sparse한 상황에서 SVM은 부적절하다 : Cannot learn reliable parameters(hyperplanes) in complex(non-linear) kernel spaces
- FM은 복잡한 feature interaction도 모델링하고, factorized parametrization을 사용한다(뒤에 설명)
- Linear Complexity이며, linear number of parameters이다 : 성능 좋은데, 계산복잡도 낮다
Contributions
- sparse data
- linear complexity
- general predictor
1. Prediction Under Sparsity
- 일반적으로 볼 수 있는 영화 평점 데이터의 설명이다.
- Matrix Factorization은 user와 movie, 그리고 해당 rating만 사용한다.
-
안 본 것은 sparse data가 됨.
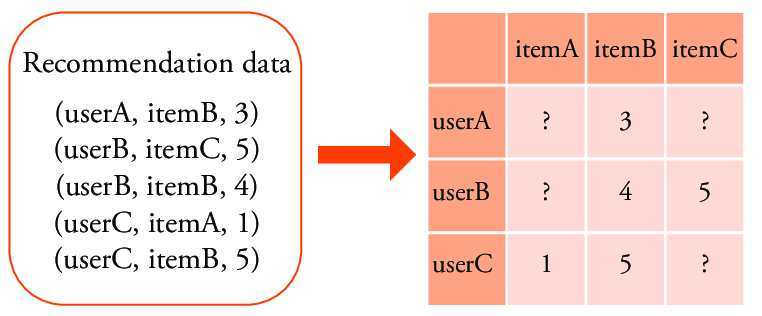
-
- Factorization Machine은 time정보 같은 metadata 등을 추가로 구성하는 등 observed data로 다양하게 사용할 수 있다.

- 따라서 다음과 같은 feature vector x를 구성할 수 있다.
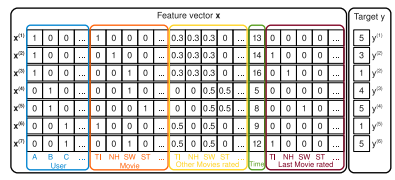
- 파란색 : user의 원핫벡터 / 주황색 : item의 원핫벡터
- 노란색 : user가 평가한 다른 item(implicit indicators)
- 초록색 : time (메타데이터 implicit indicators)
- 갈색 : Active item을 평가하기 바로 직전 평가한 item
- target : 예측 평점
2. Model Equation
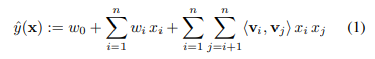
- w0 : global bias
- wi : i번째 weight를 모델링한다
- xi : feature vector
- 추정해야할 파라미터
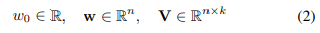
- size k의 두 벡터를 내적한다 : 이부분이 factorized된 부분. 이 부분 덕분에 linear
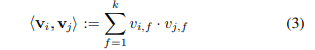
- 2-way FM(degree=2) : 개별 변수 또는 변수간 interaction 모두 모델링한다.
- 다항 회귀와 매우 흡사하지만, coefficient(계수) 대신 파라미터마다 embedding vector를 만들어서 내적한다.
- cf) Matrix Factorization에서의 식
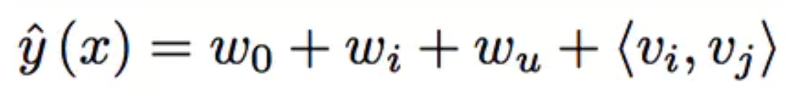
- 식 정리하자면
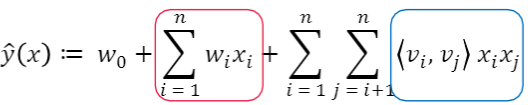
- 앞부분
- Matrix Factorization은 W_u × W_i : user와 item간의 interaction(latent factor)만 본다
- Factorization Machine은 W_i × x_i : x_i마다 구한다. 각각의 feature interaction 다 본다
- 뒷부분
- 변수간 latent vector 조합을 고려한다.
- 이때, degree=2인 경우 모든 interaction을 얻을 수 있다.
- pairwise feature interaction을 고려하기 때문에 sparse한 환경에 적합하다
2. Model Equation - Linear complexity
- Factorization of pairwise interaction
- pairwise interaction 식을 정리하면 다음과 같다.
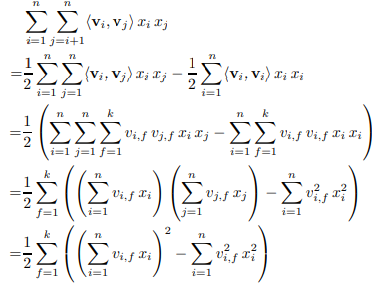
- 계산 복잡도가 O(kn^2)에서 O(kn)으로 줄었음
3. General Predictor
- FM 적용할 수 있는 것
- Regression : Least Square error 활용
- Binary claasification : 0 또는 1(부호)을 예측, logit loss
- Ranking : 점수로 order를 설정, pairwise classification loss
- 위의 경우 과적합을 막기위해 regularization 쓸 수 있다.
Learning Factorization Machines
- 학습은 gradient descent method로.
- 여기서도 linear time comlexity

d-way Factorization Machine
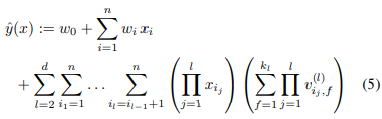
- 2-way FM을 d-way FM으로 일반화할 수 있다
- 마찬가지로 computation cost는 linear임
- http://www.libfm.org에 활용가능한 패키지 공개함
Experiment
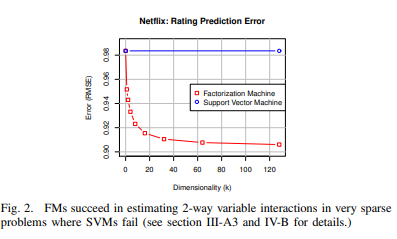
- SVM과 비교시 다차원에서도 잘 예측함
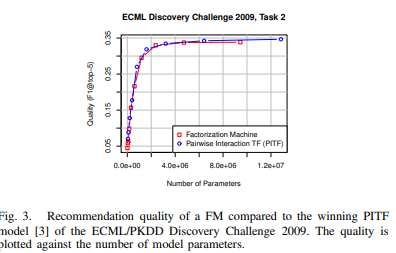
- 당시 SOTA와 비교시, 성능은 비슷한데, 당시 SOTA는 특정 태스크인 ECML에만 성능 높은 반면, FM은 general predictor로 쓰일 수 있다는 장점을 역설할 수 있음
Conclusion
- Factorized Interaction을 사용해서 feature vector x의 모든 가능한 interaction을 모델링한다
- High sparse한 상황에서 tuple처럼 만들어 interaction을 추정할 수 있다. unobserved interaction에 대해서도 일반화할 수 있다.
- 파라미터 수, 학습과 예측 시간 모두 linear하다 (Linear Complexity)
- 이는 SGD를 활용한 최적화를 진행할 수 있고 다양한 loss function을 사용할 수 있다.
- SVM. matrix, tensor and specialized factorization model보다 더 나은 성능을 증명했다.
What’s Next?
- 상황인지 추천 + feature selection + FM 논문 리뷰
- Fast context-aware recommendations with factorization machines (2011) 525
- 컨텍스트 정보를 모델링하고 context-aware rating prediction을 제공하기 위해 FM(Factorization Machine)을 적용할 것을 제안
- Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks (2017) 396
- FM은 모든 feature interaction이 동일하게 유용하고 예측 가능한 것은 아니기 때문에 동일한 가중치를 가진 모든 feature interaction의 모델링으로 인해 방해받을 수 있음. AFM(Attentional Factorization Machine)이라는 새로운 모델을 제안하여, neural attention 네트워크를 통해 데이터에서 각 feature interaction 의 중요성을 학습함
- Feature Selection for FM-Based Context-Aware Recommendation Systems (2017) 6
- FM은 입력 데이터를 이진 공간 영역에서 원-핫 인코딩된 특징 벡터로 요구. 컨텍스트의 중요성을 결정하기 위해 이진 공간에서 FM 매개변수의 값을 사용. 이진 공간에서 중요한 기능의 밀도를 고려하여 원본 데이터에서 관련 feature의 순위를 지정하고 선택
- A context-aware recommendation approach based on feature selection (2021) 2
- 임베디드 feature selection 을 기반으로 하는 상황 인식 추천 접근 방식을 제안. 모든 컨텍스트 정보의 최소 하위 집합을 생성하여 컨텍스트 중복성을 제거하고 각 컨텍스트에 적절하게 가중치를 할당함.
- FM 논문 구현
